
The types of AI experiments worth running are systematic, component-isolating tests that deliver measurable improvements and production-ready validation across prompt logic, retrieval pipelines, and full agent behavior. AI professionals who skip structured experimentation ship systems that degrade silently. The core experiment categories are prompt experiments, Retrieval-Augmented Generation (RAG) tests, agent-level end-to-end validation, and advanced online methods like multi-armed bandits. Tools like Arthur.ai, LaunchDarkly, and Open Collider each address a different layer of this stack. Getting the sequence right is what separates teams that iterate fast from teams that debug in production.
1. prompt experiments: the fastest iterative AI test
Prompt experiments are isolated tests of natural language prompts run against fixed evaluation datasets. They are the lowest-cost, highest-velocity experiment type available to AI teams. Because the dataset is fixed, every prompt variant gets evaluated under identical conditions, making regressions immediately visible.

The core benefit is speed. A team can test dozens of prompt variants in a single afternoon without touching the retrieval layer or the agent orchestration logic. Arthur.ai’s experimentation framework demonstrates this directly: Upsolve used prompt evaluation pipelines to catch regressions in SQL generation across multiple database types before those regressions ever reached production. One firm using this approach increased success rates from 79% to 100% on evaluation datasets after isolating and fixing a single regression through prompt experiments. That is a 21-point lift from one targeted test.
Key use cases for prompt experiments include:
- Regression detection: Catching output quality drops when prompt templates change
- Variant comparison: Testing instruction phrasing, role definitions, and output format constraints
- Model migration: Validating that a new model version produces equivalent or better outputs before swapping
- Edge case coverage: Stress-testing prompts against adversarial or ambiguous inputs
Pro Tip: Store all prompt variants in a templated library with version control. This lets you swap and retest any variant in minutes and keeps your experiment history auditable.
Semantic collision engines, such as those in the Open Collider repository, outperform standard prompting methods in head-to-head evaluations by 53–59% across benchmark scenarios. That margin is large enough to justify dedicated prompt experimentation infrastructure in any production AI system.
2. RAG experiments: fixing hidden retrieval failures
Retrieval-Augmented Generation (RAG) experiments test the retrieval layer of an AI pipeline in isolation from the agent that consumes its outputs. Bad retrieval is the most common hidden root cause of agent failure, and it is nearly invisible when you only evaluate at the agent output level.
The problem is that agent-level metrics average over many failure modes. A retrieval failure that returns the wrong document chunk looks identical to a reasoning failure at the output level. RAG experiments break that ambiguity by measuring retrieval quality directly.
Components to test in RAG experiments include:
- Chunking strategy: Sentence-level vs. paragraph-level vs. semantic chunking and their effect on retrieval precision
- Embedding model selection: Comparing embedding models on domain-specific retrieval benchmarks
- Index configuration: Testing approximate nearest neighbor parameters, re-ranking layers, and hybrid search configurations
- Query rewriting: Evaluating whether query expansion or rewriting improves recall on ambiguous user inputs
Pro Tip: Build a retrieval-specific evaluation dataset with known query-document relevance pairs before running RAG experiments. Without ground truth, you cannot measure whether a chunking change actually improved retrieval or just changed it.
Isolating retrieval testing from agent experiments exposes failure modes that composite metrics hide entirely. Teams that skip this step routinely misattribute retrieval failures to prompt quality and spend weeks optimizing the wrong layer.
3. agent-level end-to-end experiments
Agent experiments evaluate the full AI system using known inputs and expected outputs that simulate real user behavior. They are more expensive than prompt or RAG experiments, but they are the only test type that validates whether isolated improvements actually hold up in the complete pipeline.
The key distinction is fidelity. Prompt experiments tell you a prompt variant scores better on a fixed dataset. Agent experiments tell you whether that better prompt, combined with your retrieval layer and your tool-calling logic, produces better outcomes for real tasks. The best practice is to run agent experiments after prompt and RAG experiments have already narrowed the candidate set. Running agent experiments first wastes compute on variants that would have been eliminated cheaply.
Structured agent experiments rely on supervised evaluations with ground truth. This means:
- Defining a representative task set that covers your production use case distribution
- Labeling expected outputs or outcomes for each task
- Running candidate agent configurations against the full task set
- Scoring results with automated metrics and, where needed, human review
The cost-benefit tradeoff is real. Agent experiments consume more tokens, more time, and more reviewer effort than isolated tests. They are worth that cost when you are validating a change before a production promotion, not during early exploration. Understanding the types of AI agents you are testing also matters, since orchestration complexity varies significantly across agent architectures.
4. classic a/b testing in AI production systems
A/B testing in AI production systems assigns users randomly to a control variant and a treatment variant, then measures a business metric to determine which performs better. LaunchDarkly’s framework makes a critical distinction: offline evaluation measures quality while online experimentation measures actual business lift with statistical significance on real users. Most teams confuse the two, which leads to shipping changes that pass evals but fail in production.
Classic A/B testing works well when:
- You have sufficient traffic to reach statistical significance within an acceptable time window
- The metric you care about is directly observable at the user level
- Variants do not interfere with each other through shared state or resources
The limitation is opportunity cost. During an A/B test, a fraction of your traffic is receiving the inferior variant. For high-traffic systems, that cost is acceptable. For lower-traffic enterprise deployments, it can be prohibitive. This is where adaptive methods become necessary.
5. multi-armed bandits and adaptive experimentation
Multi-armed bandits are the right experiment type when you have multiple prompt or model variants competing for production traffic and you want to minimize the time spent serving inferior options. Modern AI products use bandits for prompt variant selection and recommender model selection, where many candidates exist but only one can serve production traffic at any given moment.
The mechanism is straightforward. A bandit algorithm allocates more traffic to variants that are performing better in real time, while continuing to explore lower-performing variants at a reduced rate. This contrasts with classic A/B testing, where traffic splits are fixed regardless of early performance signals.
“Traditional A/B testing is often inadequate for modern AI products. More adaptive methods like multi-armed bandits provide faster and more cost-effective optimization.” — Production AI/ML Engineering practice
Adaptive online experimentation techniques like multi-armed bandits significantly reduce the time and opportunity cost inherent in classical A/B testing for AI model variants. For teams running continuous prompt optimization across high-traffic systems, bandits are not optional. They are the standard.
6. interleaved tests and switchback designs
Interleaved testing and switchback testing address two specific scenarios where classic A/B tests and bandits both fall short.
Interleaved tests are designed for ranking and retrieval systems. Instead of showing user A one ranked list and user B another, interleaved tests show a single user a merged list drawn from both variants, then measure which variant’s items get selected. Interleaved tests converge faster for ranking and retrieval evaluation because each user interaction generates a direct comparison signal rather than a noisy aggregate metric.
Switchback tests apply to two-sided marketplaces and shared-resource platforms where user-level randomization is impossible. In a ride-sharing or staffing platform, assigning individual users to variants creates interference because supply and demand interact. Switchback designs alternate the entire system between variants on a time-based schedule, then compare outcomes across time windows. Meta and Google both use switchback designs for marketplace experiments where network effects make user-level splits invalid.
The right choice between these methods depends on your system architecture. Ranking systems benefit from interleaved tests. Marketplace systems require switchback designs. Neither is a universal replacement for A/B testing. They are specialized tools for specific interference patterns.
7. planning-mode experiments for complex AI code generation
Planning-mode experiments apply specifically to AI code generation tasks that touch multiple files or require coordinated changes across a codebase. For features touching three or more files, planning mode cuts overhead versus direct execution, despite the added initial time investment. For simpler, single-file fixes, planning mode adds overhead without benefit.
This experiment type matters for AI engineering teams using tools like Claude Code or similar agentic coding assistants. The experiment is straightforward: run the same task in planning mode and direct execution mode, then compare total time, error rate, and backtracking frequency. The results are task-complexity-dependent, which means the experiment needs to be run across a representative sample of your actual task distribution, not just on a few cherry-picked examples.
Pro Tip: Segment your task backlog by file-touch count before running planning-mode experiments. Tasks touching one or two files will skew your results if mixed with multi-file tasks.
8. how to choose the right AI experiment type
Selecting the right experiment type depends on four criteria: iteration speed required, cost tolerance, fidelity needed, and available traffic volume. The hierarchical isolation approach is the most effective method for AI experimentation. Start with prompt and RAG experiments before moving to full agent testing.
| Experiment Type | Best For | Cost | Fidelity |
|---|---|---|---|
| Prompt experiments | Rapid iteration, regression detection | Low | Medium |
| RAG experiments | Retrieval quality, chunking, embeddings | Low | Medium |
| Agent-level experiments | Pre-production validation | High | High |
| Classic A/B tests | High-traffic production metrics | Medium | High |
| Multi-armed bandits | Continuous optimization, many variants | Medium | High |
| Interleaved tests | Ranking and retrieval systems | Low | High |
| Switchback tests | Marketplace, shared-resource systems | Medium | High |
Budget and resource constraints should drive sequencing. Prompt and RAG experiments cost almost nothing relative to agent experiments and production tests. Run them first. Promote only the variants that survive isolated testing to agent-level validation. Promote only agent-validated changes to production A/B or bandit experiments.
Governance also matters at scale. A structured AI governance framework defines guardrails for what changes require which level of validation before production promotion. Without that structure, teams skip steps under deadline pressure and ship regressions.
Key takeaways
The most effective AI experimentation strategy sequences prompt and RAG experiments first, validates end-to-end with agent experiments, then uses adaptive online methods to optimize production performance.
| Point | Details |
|---|---|
| Start with prompt experiments | They are the lowest-cost, fastest-feedback experiment type and catch regressions before they reach production. |
| Isolate retrieval testing | Bad retrieval is the most common hidden agent failure mode and is invisible without dedicated RAG experiments. |
| Sequence before scaling | Run prompt and RAG experiments before agent-level tests to avoid wasting compute on weak variants. |
| Use bandits over static A/B | Multi-armed bandits reduce opportunity cost in high-traffic systems with multiple competing variants. |
| Match method to system type | Interleaved tests suit ranking systems; switchback designs suit marketplaces with network interference. |
What i’ve learned running AI experiments at scale
Most teams I’ve seen start their AI experimentation programs at the wrong layer. They jump straight to production A/B tests because that is what they know from web product work. The result is slow feedback cycles, high compute costs, and regressions that survive into production because the evaluation signal was too noisy to catch them.
The insight that changed my thinking was the distinction between offline evaluation and online experimentation. Evaluation shows whether a change passes a quality bar. Experimentation measures whether it moves a business metric on real users. Both are necessary. Neither replaces the other. Teams that conflate them end up either shipping changes that look good in evals but fail in production, or running expensive production tests on changes that should have been eliminated offline.
The other thing I’d push back on is the assumption that multi-armed bandits are only for large-scale consumer products. I’ve seen enterprise teams with moderate traffic volumes benefit significantly from bandit-based prompt optimization, specifically because they cannot afford the opportunity cost of long A/B test windows. The math works in your favor even at lower traffic levels when the number of variants is high.
Retrieval failures are the silent killer. I’ve watched teams spend months optimizing prompts for an agent that was failing because of a chunking configuration set during initial setup and never revisited. Isolated RAG experiments would have surfaced that in a day. Build them into your standard workflow before you touch anything else.
— TekkrTools
Turn your AI experiments into measurable organizational results
Running the right experiments is only half the equation. The other half is knowing whether your AI tools are actually being used, by whom, and at what cost across your organization.
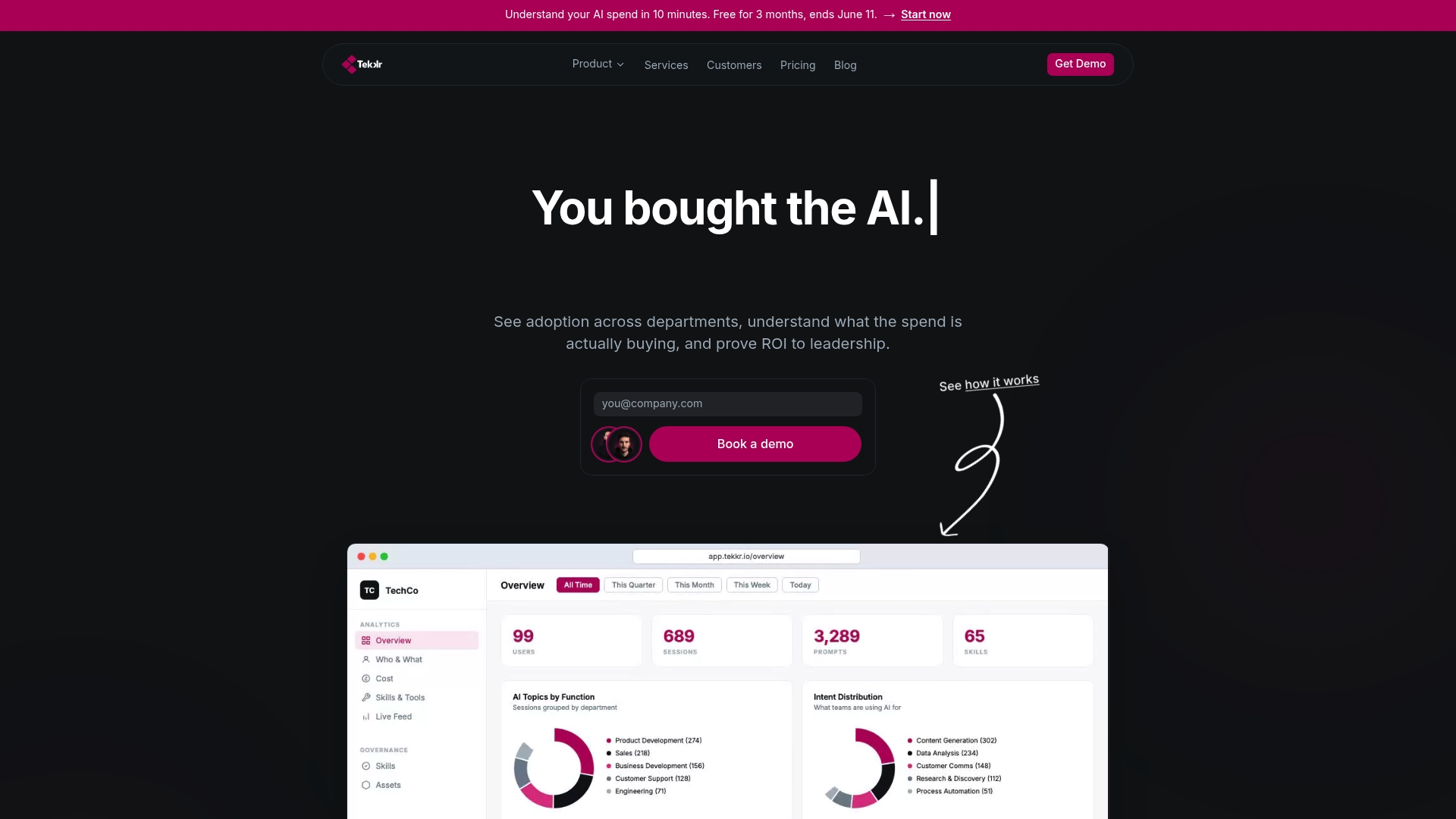
Tekkr’s AI adoption platform gives you the visibility and enablement infrastructure to turn experiment results into production habits. Configurato tracks real usage of tools like Claude and Codex by team, surfaces which use cases are generating value, and drives adoption through gamified rollouts and company-wide AI playbooks. If you are running structured AI experiments and want to connect those results to measurable productivity gains across every department, Tekkr is built for exactly that. Setup takes 10 minutes, no credit card required.
FAQ
What are the most effective AI experiment types for production systems?
Prompt experiments, RAG experiments, and agent-level end-to-end tests form the core hierarchy. Advanced online methods like multi-armed bandits and interleaved tests optimize production performance after offline validation is complete.
How do prompt experiments differ from offline model evaluation?
Prompt experiments test specific prompt variants against fixed datasets to detect regressions and compare outputs. Offline evaluation measures whether a system passes a quality bar. Experimentation measures actual business lift with statistical significance on real users.
When should you use multi-armed bandits instead of a/b tests?
Use multi-armed bandits when you have multiple competing variants and cannot afford the opportunity cost of serving an inferior variant to a fixed traffic split for the duration of a standard A/B test window.
Why is retrieval testing critical in rag-based AI systems?
Bad retrieval is the most common hidden root cause of agent failure. Retrieval failures are invisible at the agent output level and require isolated RAG experiments to detect and measure accurately.
How many files should a task touch before using planning-mode experiments?
Planning-mode experiments become cost-effective for tasks touching three or more files. For simpler single-file tasks, planning mode adds overhead without measurable benefit.