
Data privacy in AI is defined as the set of principles, technical controls, and legal obligations that govern how personal information is collected, processed, stored, and deleted within artificial intelligence systems. The role of data privacy in AI extends far beyond regulatory checkbox compliance. GDPR violations can reach €20 million or 4% of worldwide annual turnover, and the EU AI Act raises that ceiling to €35 million or 7%. Those numbers signal that privacy failures carry existential financial risk. For AI professionals rolling out tools across organizations, understanding data protection in AI is the difference between building trustworthy systems and building liability.
What is the role of data privacy in AI systems?
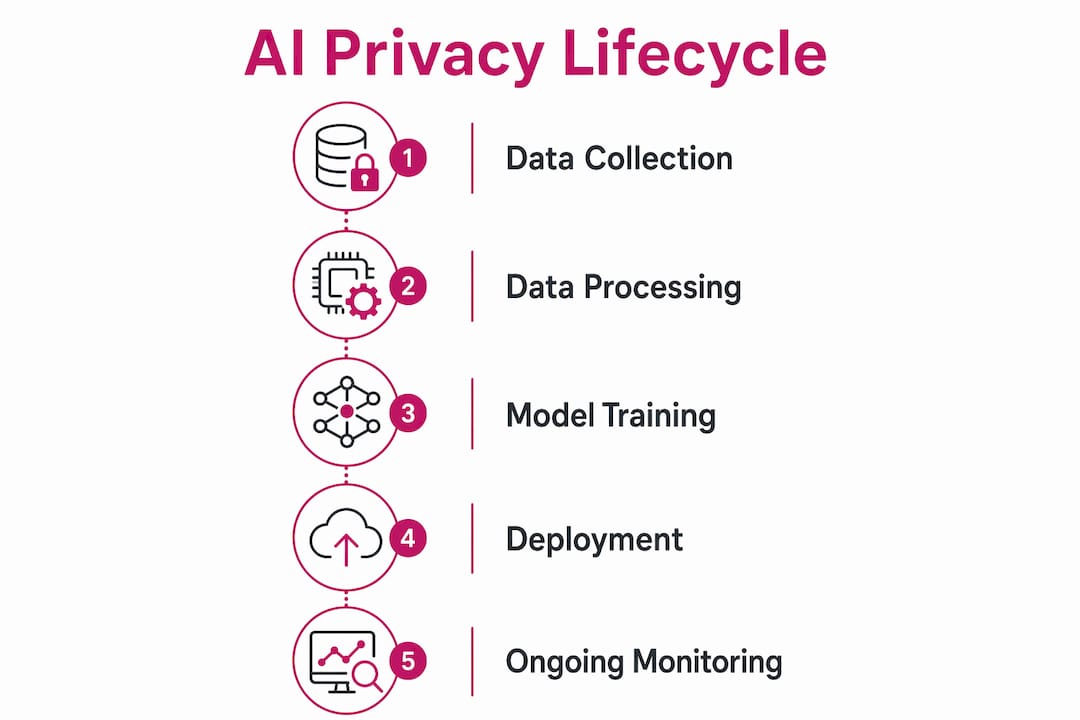
Data privacy in AI governs every stage of how a model interacts with personal information, from the moment training data is selected to the day a system is decommissioned. The industry term for this discipline is privacy by design, a principle that embeds data protection requirements into system architecture rather than bolting them on after deployment.
Privacy by design means that privacy controls are not optional add-ons. They are structural requirements built into every phase of the AI lifecycle. This approach shifts the question from “Are we compliant?” to “Is privacy the default behavior of this system?”
The strategic importance of this shift is significant. Organizations that treat privacy as a foundational design requirement reduce remediation costs, avoid regulatory scrutiny, and build systems that users trust. Privacy governance is not a legal department problem. It is an engineering and product leadership responsibility.

How is data privacy embedded across the AI lifecycle?
Operationalizing privacy across an AI system’s full lifecycle requires discipline at each phase. The following stages define where privacy controls must be active.
-
Data selection and training. Use anonymized, pseudonymized, or synthetic data wherever possible. Conduct a Data Protection Impact Assessment (DPIA) before training begins on any personal data. For high-risk AI systems, combining a DPIA with a Fundamental Rights Impact Assessment (FRIA) into a single document saves time and ensures consistent coverage across both GDPR and EU AI Act requirements.
-
Model development and testing. Apply data minimization at the prompt and tool-call layer. Pre-prompt redaction intercepts and strips personal data before it reaches the model, technically enforcing GDPR’s minimization principle. This is the most effective point to prevent raw personal information from entering a model’s context window.
-
Deployment and ongoing processing. Implement continuous data discovery to identify where personal data flows through production systems. Audit model outputs regularly for unintended personal data exposure. Document all processing activities under Article 30 of GDPR.
-
Decommissioning. Deleting training datasets does not end privacy obligations. Model weights and parameters may still contain personal information, requiring corrective action that addresses the model itself, not just the source data.
Pro Tip: When building your DPIA, map every data flow before writing a single line of policy. Undocumented flows are the most common source of GDPR enforcement findings.
Tekkr’s Configurato platform handles one of the most overlooked lifecycle risks: prompt-level data exposure. Its architecture automatically strips PII from prompts before processing, with no browser extensions required. That is privacy by design applied at the exact layer where most organizations leave personal data exposed.
What are the specific data privacy risks in AI models?
AI models carry privacy risks that differ fundamentally from traditional software. The core issue is that a model trained on personal data does not automatically become anonymous once training is complete.
Models may retain personal data in ways that enable extraction through adversarial probing or model inversion attacks. An attacker who queries a model with carefully crafted inputs can sometimes reconstruct training examples, including names, addresses, or medical records. This risk exists even when the original dataset has been deleted.
Key data privacy risks specific to AI include:
- Memorization of personal data. Large language models can memorize and reproduce verbatim text from training data, including personal identifiers.
- Inference attacks. Adversaries can infer sensitive attributes about individuals by analyzing model outputs, even without direct access to training data.
- Residual data in model parameters. Deleting source datasets does not remove personal data embedded in model weights. Remediation must address the model itself.
- Third-party model risk. Using pre-trained models from external providers means inheriting their training data privacy risks, which may not be fully documented.
“Misconceptions persist about AI anonymity. Evolving standards require documentation and ongoing privacy risk evaluation, not one-time assessments.” — Privacy, GDPR, and Personal Data in AI Models
Documented, case-by-case assessments of model data exposure are not optional under GDPR. They are the only defensible position when a regulator asks whether your AI system processes personal data.
What does the 2026 regulatory landscape mean for AI compliance?
The regulatory environment for AI data privacy has hardened considerably. Two frameworks now define the compliance floor for most organizations operating in or selling into the European Union.
GDPR remains the primary data protection regulation. It applies to any AI system that processes personal data of EU residents, regardless of where the organization is based. Fines reach €20 million or 4% of global turnover, whichever is higher.
The EU AI Act adds a second compliance layer specifically for AI systems. High-risk AI applications face fines of up to €35 million or 7% of global turnover for the most serious violations. That ceiling exceeds GDPR, making the AI Act the higher-stakes regulation for organizations deploying AI in regulated sectors like healthcare, finance, or hiring.
| Regulation | Maximum Fine | Scope |
|---|---|---|
| GDPR | €20M or 4% of global turnover | Personal data processing |
| EU AI Act | €35M or 7% of global turnover | High-risk AI systems |
Outside Europe, the FTC has made algorithmic accountability and privacy a stated enforcement priority. Organizations operating in the United States face parallel scrutiny on how AI systems use personal data, particularly in consumer-facing applications.
The practical implication is clear. AI compliance regulations in 2026 are not theoretical. Enforcement actions are active, fines are material, and regulators have developed the technical expertise to investigate AI systems directly. For AI professionals, staying current on governance trends is a business continuity requirement, not a legal formality.
How does data privacy become a competitive advantage in AI?
The most forward-thinking organizations have stopped treating data privacy as a cost center. Organizations that treat privacy as a trust-building asset gain measurable competitive advantage in AI-driven markets. Customers and enterprise buyers increasingly require documented privacy practices before signing contracts.
The shift from defensive compliance to proactive privacy governance produces concrete business outcomes:
- Faster procurement cycles. Vendors with documented GDPR and EU AI Act compliance clear enterprise security reviews faster than those without.
- Higher user trust scores. Products that communicate privacy protections clearly see stronger user engagement and lower churn.
- Reduced incident costs. Organizations with privacy by design architectures spend less on breach response and regulatory remediation.
- Market differentiation. In sectors where AI adoption is high and trust is low, privacy-first positioning is a genuine differentiator.
The systemic approach matters here. Shifting the privacy burden from individual users to organizational systems, through techniques like federated learning and automatic PII stripping, makes privacy the default rather than the exception. That design choice signals maturity to regulators, partners, and customers alike.
Pro Tip: Document your privacy architecture in plain language for non-technical stakeholders. A one-page privacy summary for procurement teams closes deals faster than a 40-page compliance report.
Building a competitive AI advantage requires treating privacy governance as a product feature, not a legal constraint. The organizations winning in AI-driven markets are the ones that made this shift early.
Key Takeaways
Effective data privacy in AI requires embedding technical controls, regulatory compliance, and governance practices at every stage of the AI lifecycle, not just at deployment.
| Point | Details |
|---|---|
| Privacy by design is non-negotiable | Embed data protection controls from training data selection through model decommissioning. |
| Model deletion is not enough | Deleting training data does not remove personal data from model weights; remediation must address the model itself. |
| Regulatory fines are material | EU AI Act fines reach €35M or 7% of global turnover, exceeding GDPR’s already significant penalties. |
| Pre-prompt redaction is the strongest control | Intercepting and stripping PII before it reaches the model technically enforces GDPR data minimization. |
| Privacy drives competitive advantage | Organizations with documented privacy practices close enterprise deals faster and build stronger user trust. |
Privacy governance is the real AI differentiator
The organizations I see struggling most with AI implementation are not the ones that lack technical talent. They are the ones that treated privacy as a legal sign-off rather than an engineering requirement. By the time a regulator or enterprise buyer asks hard questions, the architecture is already wrong and fixing it is expensive.
The uncomfortable truth about ethical AI and privacy is that most AI systems were not built with privacy by design. They were built fast, trained on whatever data was available, and then handed to legal teams to retroactively document. That sequence produces compliance theater, not compliance. Regulators in 2026 know the difference.
What actually works is treating privacy as a constraint that shapes system design from day one. That means using synthetic or anonymized data in training, building prompt-layer redaction into your infrastructure, and running unified DPIA and FRIA assessments before deployment, not after. It also means accepting that some use cases are not viable if they require processing personal data at scale without a lawful basis.
The emerging privacy-preserving technologies, federated learning, differential privacy, and secure multi-party computation, are becoming practical for production systems. They are not academic concepts anymore. Organizations that build fluency in these techniques now will have a structural advantage as regulations tighten and customer expectations rise.
Privacy governance is not a constraint on AI innovation. It is the foundation that makes AI innovation sustainable.
— TekkrTools
Tekkr’s approach to AI privacy and governance
AI teams that want measurable results from their AI investments need more than adoption dashboards. They need a platform built with privacy at its core.
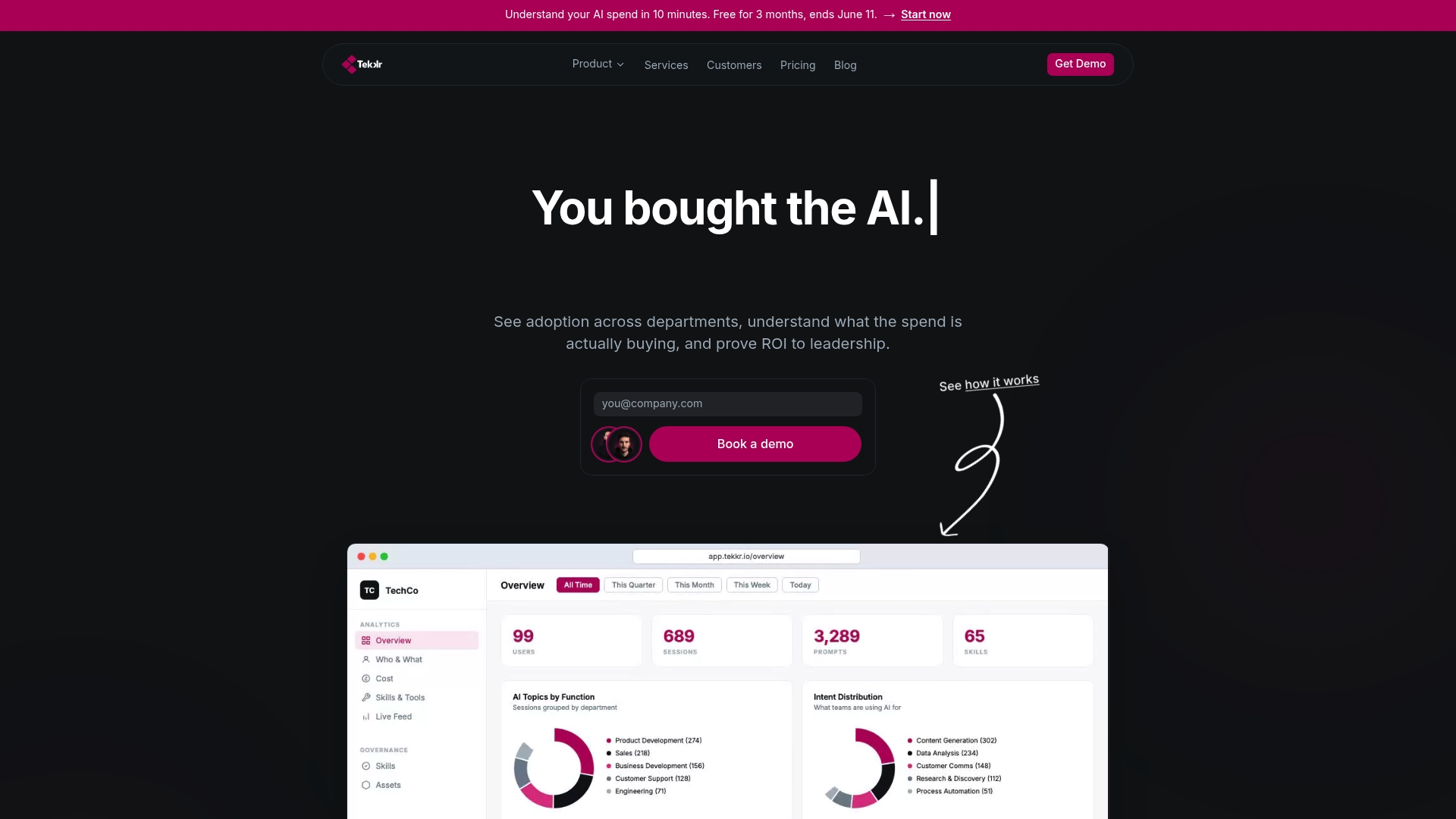
Tekkr’s Configurato tracks AI adoption, spend, and return across every team while running on a privacy-first architecture that is end-to-end encrypted, GDPR-compliant, and strips PII from prompts automatically. No browser extensions. No raw personal data exposed to models. Setup takes about 10 minutes. For organizations serious about AI adoption with governance built in, Tekkr offers a free tier with no credit card required. You bought the AI. Tekkr helps you prove it is working, without compromising the privacy of the people using it.
FAQ
What is the role of data privacy in AI?
Data privacy in AI governs how personal information is collected, processed, and protected throughout an AI system’s lifecycle. It covers legal compliance, technical controls, and ethical obligations that prevent unauthorized use or disclosure of personal data.
How does GDPR apply to AI systems?
GDPR applies to any AI system that processes personal data of EU residents, regardless of where the organization operates. Violations can result in fines up to €20 million or 4% of global annual turnover.
Does deleting training data satisfy GDPR obligations?
Deleting training data does not end privacy obligations if the model retains or can reconstruct personal data from its weights or parameters. Remediation must address the model itself, not just the source dataset.
What is privacy by design in AI?
Privacy by design is the practice of embedding data protection requirements into AI system architecture from the earliest design phase. It means privacy is the default behavior of the system, not an afterthought added after deployment.
How do AI compliance regulations differ between GDPR and the EU AI Act?
GDPR governs personal data processing broadly, with fines up to €20 million or 4% of turnover. The EU AI Act specifically targets high-risk AI systems and carries higher maximum fines of €35 million or 7% of global turnover.