
Enterprises that skip systematic AI output optimization don’t just get mediocre results. They get costly rework cycles, compliance failures, and AI adoption numbers that look great on a dashboard but deliver nothing on the bottom line. Measurable business outcomes like reduced rework and improved time-to-publish are achievable, but only when you treat output quality as a disciplined engineering problem rather than a prompt-writing exercise. This guide walks you through the requirements, execution steps, and validation methods that actually move the needle at enterprise scale.
Table of Contents
- Define requirements and prepare for optimization
- Optimize prompts and model configuration for enterprise outcomes
- Operationalize governance and continuous monitoring
- Evaluate retrieval augmented generation (RAG) and align with business processes
- Our view: why infrastructure, edge-case handling, and process integration beat clever prompts
- Take the next step: enterprise-grade analytics and governance tools
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Set clear requirements | Defining measurable output requirements and critical failure modes is the foundation for successful AI optimization. |
| Optimize systematically | Treat prompts and model settings as code and apply structured testing, scoring, and automated feedback cycles. |
| Govern and monitor outputs | Continuous observability, policy enforcement, and cost-quality tracking ensure reliable results and business alignment. |
| Handle edge cases | Explicitly address ambiguous, adversarial, and conflict scenarios for resilient enterprise AI systems. |
| Drive business impact | Optimized AI output leads to measurable gains like conversion lifts, faster publishing, and less rework. |
Define requirements and prepare for optimization
Having established the business stakes, you’ll want to lay strong foundations before touching a single prompt or model parameter. Skipping this phase is how enterprises end up optimizing for the wrong thing entirely.
Start by defining what good output actually means for your specific context. This sounds obvious, but most teams stop at vague criteria like “accurate” or “on-brand.” You need to identify critical failure modes too. What does a broken output look like? For a legal team, it might be a hallucinated statute. For an engineering team, it might be scaffolded code that ignores your security standards. Get specific. Write it down. Make it testable.
Next, build or select a representative evaluation dataset. Think hundreds to thousands of examples, not a handful of cherry-picked cases. Your dataset should reflect the real distribution of inputs your teams will actually use, including the messy, ambiguous, and edge-case prompts that show up in production. Data-driven prompt writing frameworks recommend grounding every optimization decision in real usage data rather than theoretical best cases.
Key requirements to lock down before you optimize:
- Output format specifications (length, structure, tone, citation style)
- Compliance constraints (PII handling, regulated terminology, brand voice rules)
- Latency thresholds acceptable for each use case
- Cost-per-request budgets by department or workflow
- Escalation triggers for outputs that fall below quality gates
Then pick your tooling. Prompt engineering platforms that support testable, structured prompts are worth the setup cost. Frameworks like DSPy enable programmatic prompt optimization with automated scoring. Evaluation harnesses let you run regression tests every time you change a prompt or model setting. The goal, as outlined in advanced prompt optimization practices, is to treat prompt and output quality as an engineering problem: measurable, improvable, and version-controlled.
| Requirement type | Example criteria | Why it matters |
|---|---|---|
| Output format | JSON structure, max 200 words | Enables downstream automation |
| Compliance | No PII in logs, legal disclaimers | Reduces regulatory risk |
| Latency | Under 3 seconds for customer-facing | Protects user experience |
| Cost | Under $0.02 per request | Keeps unit economics viable |
| Quality gate | Accuracy score above 85% | Triggers escalation when missed |
Pro Tip: Build your evaluation dataset before writing your first optimized prompt. Teams that do this catch failure modes they never would have anticipated, and they avoid locking in a prompt that performs well on the cases they thought of but fails on the ones that actually matter in production.
Optimize prompts and model configuration for enterprise outcomes
With requirements and representative data in place, here’s how to execute optimization cycles with measurable precision. The biggest mistake enterprises make here is treating prompt writing as a creative task rather than an iterative engineering discipline.
Treat prompts as code. That means version control, typed inputs and outputs, and structured tests that run on every change. When you draft a new prompt variant, you should be able to see whether it improved or degraded performance across your evaluation dataset, not just on the one example you were looking at. Systematic prompt engineering built on programmatic optimization frameworks and structured evaluation loops consistently outperforms ad hoc prompt tweaking.
Here’s a practical optimization sequence:
- Start with your baseline prompt and score it against your full evaluation dataset. Document the score before touching anything.
- Identify the top three failure categories from your baseline results. Prioritize fixes based on business impact, not frequency.
- Rewrite the prompt to address the highest-impact failure category. One change at a time. Test immediately.
- Run automated scoring using a framework like DSPy to compare variant performance. Accept only statistically meaningful improvements.
- Apply few-shot examples strategically. Select examples that represent your hardest cases, not your easiest ones. This is where enterprise prompt techniques diverge from basic prompting guides.
- Adjust model decoding parameters only after prompt optimization plateaus. Temperature and top_p are your next levers, not your first.
- Set stop sequences and max token limits to enforce output compliance. This prevents verbosity and ensures structured outputs stay within format requirements.
Model configuration tuning deserves more attention than most teams give it. Temperature and top_p settings are core levers for output optimization, but they interact in ways that make simultaneous changes hard to diagnose. Tune one at a time.
| Parameter | Low setting effect | High setting effect | Enterprise recommendation |
|---|---|---|---|
| Temperature | Deterministic, repetitive | Creative, inconsistent | 0.2-0.4 for structured tasks |
| Top_p | Focused vocabulary | Broader word choice | 0.9 for most enterprise tasks |
| Max tokens | Cuts off responses | Allows verbosity | Set tight per use case |
| Stop sequences | N/A | N/A | Always define for structured output |

For refining prompts in regulated industries or customer-facing workflows, lower temperature settings dramatically improve consistency. Creative use cases like marketing copy or brainstorming benefit from slightly higher settings, but even there, enterprise quality gates usually demand more control than default settings provide.
Pro Tip: Don’t skip the max token constraint. Verbose outputs that bleed past your expected length create downstream parsing failures, inflate costs, and frustrate users. Setting a tight max token limit forces the model to prioritize, and the resulting outputs are almost always more usable.
Operationalize governance and continuous monitoring
With optimization cycles running, ongoing monitoring and governance ensures enterprise alignment and reliability. This is where many implementations stall. Teams get good results in testing and then deploy without the infrastructure to catch degradation in production.
Governance and observability in production requires enterprises to enforce policy at inference time, log immutable interaction artifacts, and monitor output quality alongside latency and cost. That’s not a security team concern or a compliance checkbox. It’s core infrastructure for any enterprise betting on AI-driven workflows.
What a production governance layer must cover:
- Policy enforcement at inference, including PII detection, content filtering, and brand voice compliance checks that run before output reaches the user
- Immutable logging of prompts, model versions, outputs, and metadata for auditability and debugging
- Real-time latency monitoring including time-to-first-token and total response time, segmented by use case and user role
- Cost-per-request tracking tied to business unit budgets, not just aggregate API spend
- Feedback signal capture from end users and downstream systems, flagging outputs that get edited, rejected, or escalated
- Escalation paths with defined thresholds, so a quality drop triggers a human review process rather than just an alert nobody sees
“Optimization should always account for the tradeoff of how much it costs to get a better answer.” This framing, drawn from deep research agent architectures, applies equally to enterprise AI workflows. The most accurate output is not always the right one if it costs ten times more and returns twice as slowly as an output that is 90% as good.
Escalation design is worth dwelling on. Define specific output failure modes and the exact threshold that triggers each level of response. A minor tone deviation might just get flagged for review. A potential compliance breach should halt the workflow entirely. These gates protect the business and build the trust that drives broader AI adoption. Review safe AI use strategies for additional governance frameworks suited to commercial deployments.
Evaluate retrieval augmented generation (RAG) and align with business processes
Once monitoring and governance are in place, enterprises using RAG (retrieval augmented generation, a technique where the AI retrieves relevant documents at inference time to ground its responses) must address its unique evaluation and alignment challenges. A generic prompt quality score won’t tell you whether your retrieval pipeline is failing.
Optimizing enterprise RAG requires separating retrieval evaluation from generation evaluation. These are two distinct failure modes with different root causes and different fixes. If your retrieval step surfaces the wrong documents, the best generation configuration in the world won’t save your output quality. Test them independently before drawing conclusions about where the problem lives.
Core RAG evaluation dimensions:
- Retrieval precision: Are the top-ranked documents actually relevant to the query?
- Retrieval recall: Are all the necessary documents being surfaced, or is critical context missing?
- Faithfulness: Does the generated response accurately reflect what the retrieved documents actually say?
- Citation coverage: Are claims in the output properly grounded in retrieved sources?
- Answer relevance: Does the final output actually answer the user’s question, or does it answer what the documents contain?
Include enterprise-relevant edge cases in your evaluation set. Conflicting documents are common in real enterprise knowledge bases, and your RAG system needs a defined behavior for handling them rather than confidently synthesizing contradictory information. “No answer” scenarios, where the right response is to say the information isn’t available, are equally important and frequently undertested.
| Error mode | Best fix | When to use |
|---|---|---|
| Domain knowledge gap | RAG | Missing context not in training data |
| Format or compliance failure | Prompt engineering | Output structure or policy violations |
| Persistent accuracy issues | Fine-tuning | Systematic errors across many examples |
| Output structure or safety | Post-processing validation | Final quality gate before delivery |
Choosing between prompt engineering, RAG, and fine-tuning should always be driven by your dominant error mode, not by what’s trendy or what your vendor recommends. Integrate RAG feedback signals into your business processes. When a retrieval failure causes a downstream workflow error, that signal should flow back to the team managing your knowledge base, not just sit in a monitoring dashboard. Explore RAG optimization techniques for deeper guidance on building those feedback loops.
Pro Tip: Score your RAG system on “no answer” cases explicitly. If your evaluation set only includes queries where the right answer exists in your knowledge base, you’ll never know how your system behaves when it doesn’t, and that’s exactly when hallucination risk is highest.
Our view: why infrastructure, edge-case handling, and process integration beat clever prompts
Let’s be direct about something most AI optimization content won’t say: prompt engineering alone will not scale. It’s necessary, but it’s nowhere near sufficient for enterprise-grade results.
The enterprise optimization work that actually moves the needle isn’t about crafting the perfect system prompt. It’s about building the infrastructure to detect when things go wrong, the evaluation discipline to understand why, and the process integration to route those insights back to the people who can act on them.
Edge cases are where this becomes critical. Adversarial inputs, ambiguous queries, and conflicting source documents are not rare exceptions in enterprise environments. They are the daily reality of deploying AI across large, complex organizations. Systems that haven’t been explicitly tested against these scenarios will fail on them, and they’ll often fail confidently, which is far more damaging than an obvious error. Reviewing prompt safety strategies is one starting point, but the deeper work is building adversarial test cases specific to your domain.
Governance-first infrastructure is what distinguishes the implementations that compound over time from the ones that plateau after initial deployment. Logging, evaluation gates, and human-in-the-loop escalation paths are not overhead. They are the mechanism by which your AI system gets better as your organization learns more about how it fails. Without that loop, you’re not running an optimization program. You’re running a deployment that slowly drifts out of alignment with your business needs.
The teams we see succeeding treat AI output quality the same way they treat software reliability: as a continuous discipline with clear ownership, measurable standards, and systematic improvement cycles. That mindset, not any single prompt technique, is the real competitive advantage.
Take the next step: enterprise-grade analytics and governance tools
If the strategies in this guide resonate, the next question is execution. Defining requirements, building evaluation datasets, enforcing governance at inference, and managing RAG pipelines are significant operational commitments. The gap between knowing what to do and having the infrastructure to do it at scale is where most enterprise AI programs stall.
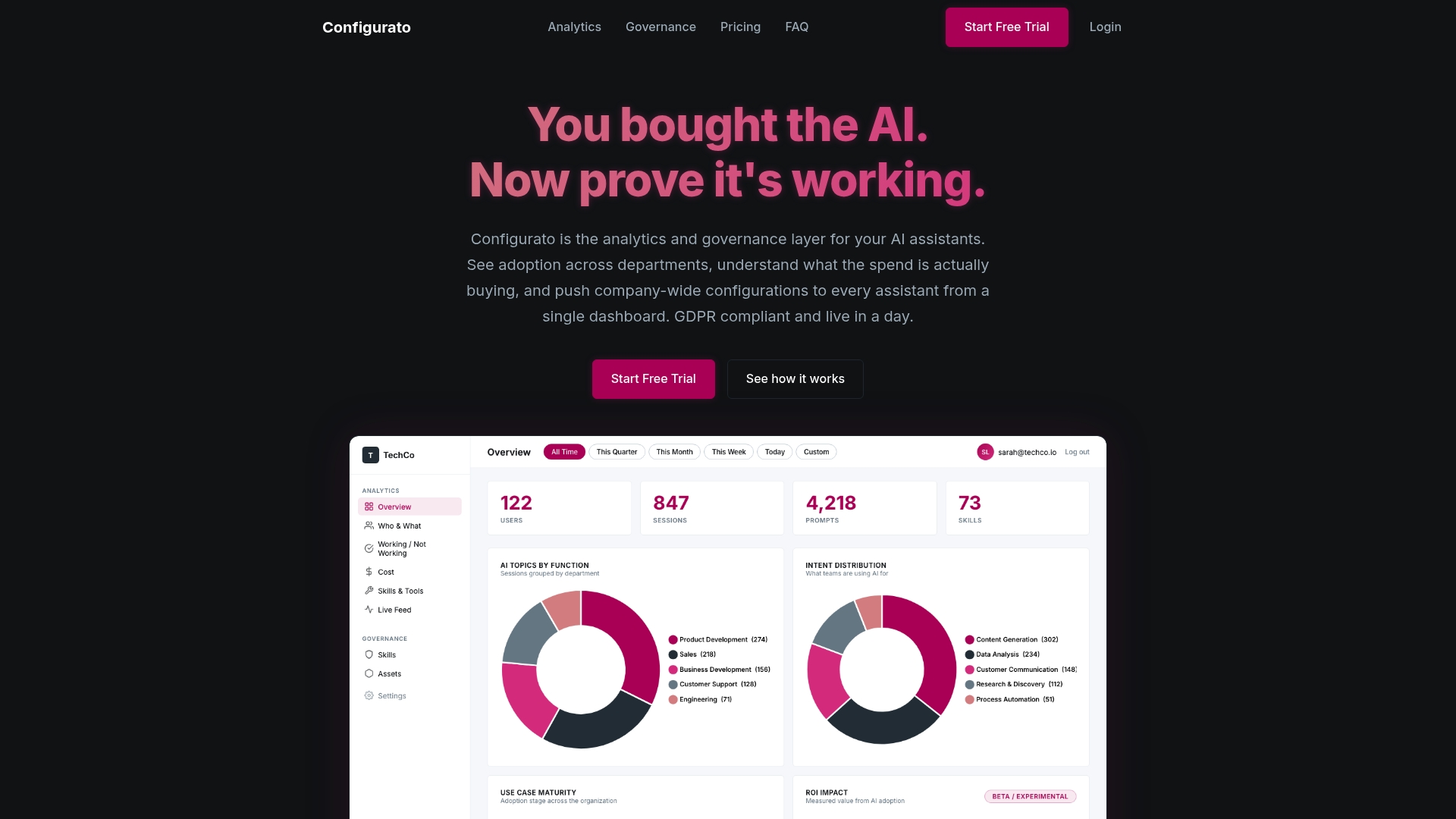
Configurato by Tekkr is built for exactly this challenge. The Configurato governance platform enables analytics, systematic output monitoring, and governance controls tailored for enterprise AI environments. It integrates prompt optimization workflows, RAG evaluation, and cost-quality tradeoff management under one dashboard, so your teams aren’t stitching together spreadsheets and ad hoc scripts. If you’re ready to move from ad hoc AI adoption to a systematic program that compounds over time, Configurato is the infrastructure layer that makes it operational.
Frequently asked questions
What are the key metrics to monitor when optimizing AI output?
Monitor accuracy, latency, cost-per-request, feedback signals, and compliance with business policies. Output quality, latency, and cost alongside escalation rates give you a complete operational picture.
How do enterprises handle ambiguous or adversarial prompts?
Robust systems explicitly test for ambiguous, adversarial, and missing-information scenarios to prevent hallucination and security failures. Effective enterprise LLM deployments treat adversarial case handling as a required evaluation category, not an optional stress test.
What is the role of model configuration in output optimization?
Temperature and top_p settings control output randomness; tune one parameter at a time and define max tokens and stop sequences for each use case. Model decoding configuration is a core optimization lever that complements but does not replace prompt engineering.
When should enterprises use RAG vs. prompt engineering vs. fine-tuning?
Choose based on your dominant error mode: use RAG for domain knowledge gaps, prompt engineering for compliance and format failures, and fine-tuning for persistent accuracy issues. Selecting the right technique based on error type prevents costly mismatches between the problem and the solution.
What are the business outcomes of optimized AI output?
Enterprises achieve higher conversion rates, reduced content rework, and improved time-to-publish through systematic AI output optimization. Documented outcomes include measurable conversion lifts and significant reductions in the manual effort required to make AI outputs usable.