
Most AI initiatives look healthy from the outside. Adoption dashboards show users logging in. Models are deployed. Reports get generated. But beneath the surface, the competitive advantage never materializes. The reason is almost always the same: organizations are tracking the wrong things, or tracking too few of them. Defining the right metrics for AI success is not a reporting exercise. It is a strategic discipline that determines whether your AI investments compound over time or quietly drain resources without delivering real outcomes.
Table of Contents
- Key Takeaways
- 1. What makes a good AI success metric
- 2. Core model performance metrics you need to understand
- 3. Operational and system health metrics
- 4. Business impact and value metrics
- 5. Risk and governance metrics
- 6. Comparing metric categories and choosing what to prioritize
- My honest take on what separates good AI measurement from theater
- See your AI investment with full clarity
- FAQ
Key Takeaways
| Point | Details |
|---|---|
| Use a multi-layer measurement approach | Track model performance, operational health, business impact, and risk metrics together, not separately. |
| Align metrics to business outcomes | Technical accuracy alone does not confirm that AI is creating organizational value. |
| Monitor continuously, not periodically | Catching model drift or bias after a quarterly review is often too late to prevent damage. |
| Prioritize cost per successful task | This metric exposes hidden failure costs that token-level cost tracking completely misses. |
| Design metrics for accountability | Scorecards should drive decisions, not just document what already happened. |
1. What makes a good AI success metric
Not every number you can pull from a dashboard deserves to be on your scorecard. Organizations that rely on a single-layer measurement approach often detect problems too late to prevent real business impact. Good AI performance metrics share a few specific qualities.
They cover more than one dimension. A metric that only tells you whether the model is accurate says nothing about whether the system is affordable, reliable, or compliant. You need coverage across technical model performance, operational health, business outcomes, and risk.
They connect to defined outcomes. A metric without a target is decoration. Every metric on your scorecard should map to a specific organizational goal, whether that is cost reduction, customer satisfaction, or regulatory compliance.
They enable fast response. Metrics that only surface in monthly board reports are not measuring AI success. They are memorializing it. Your measurement system needs to support continuous monitoring so teams can act before small problems become expensive ones.
- Coverage: Does the metric tell you something meaningful about model quality, system health, business value, or risk?
- Directionality: Is it clear whether higher or lower is better, and by how much?
- Actionability: Can a team act on a change in this metric within days, not quarters?
- Resistance to gaming: Would a team optimizing this metric in isolation make the AI initiative worse overall?
Pro Tip: Build your scorecard in layers. Operational metrics belong in daily dashboards. Business impact metrics get reviewed weekly or monthly. Risk and compliance metrics require continuous automated monitoring with alert thresholds.
2. Core model performance metrics you need to understand
Model performance is the foundation. Without it, everything else is built on sand. But static benchmark scores for foundation models do not guarantee reliable AI agents in production environments. You need production-grade metrics that reflect what actually happens in real workflows.
Here are the metrics that matter most:
- Accuracy: The percentage of correct predictions out of total predictions. Simple to understand, but dangerously misleading in imbalanced datasets. An AI flagging fraud correctly 95% of the time sounds good until you realize 95% of transactions are legitimate and it is just predicting “no fraud” every time.
- Precision and recall: Precision measures how often the model is right when it predicts a positive outcome. Recall measures how many actual positives it caught. The trade-off between these two is use-case specific. In medical diagnosis, high recall matters more. In content moderation, high precision reduces false removals.
- F1 score: The harmonic mean of precision and recall. Useful when you need a single number to balance both concerns.
- AUC (Area Under the Curve): Measures discrimination ability across all classification thresholds. Enterprise AI benchmarks report average accuracy around 81% across industries, which gives you a meaningful reference point for evaluating your own models.
- Hallucination rate: Specific to generative AI. Tracks how often the model produces confident but factually wrong output. For any AI assistant touching customer communications, legal documents, or technical specs, this number needs to be tracked and thresholded aggressively.
- Prompt pass rate: What percentage of prompts produce output that meets your quality bar without requiring rework? This is where model performance connects directly to user productivity.
3. Operational and system health metrics
Your model can be technically excellent and still fail operationally. System health metrics tell you whether the AI is actually running the way users need it to.

| Metric | What it measures | Why it matters |
|---|---|---|
| P95 latency | Response time at the 95th percentile | Averages hide the worst user experiences |
| Availability | Uptime as a percentage of expected runtime | Unreliable systems get abandoned |
| Pipeline reliability | Error rate in data ingestion and processing steps | Bad inputs produce bad outputs at scale |
| Cost per successful task | Total cost divided by successful completions | Exposes failure costs invisible in token pricing |
| Throughput | Requests handled per unit time | Reflects infrastructure capacity vs. demand |
Average latency is a trap. If your AI assistant responds in 0.5 seconds 90% of the time and 12 seconds 10% of the time, the average looks fine but one in ten users is having a frustrating experience. P95 latency, the response time at the 95th percentile, is the number that actually reflects user reality.
Cost per successful task (CPST) deserves particular attention. You calculate it by labeling each task with a binary success indicator, then dividing total expenses including retries by the count of successful completions. Most teams track token costs and think they understand their AI economics. They do not. CPST exposes what you are actually paying for value delivered, not just compute consumed.
Pro Tip: Set alert thresholds for P95 latency and availability in your monitoring infrastructure. Do not wait for user complaints to tell you the system is degraded. By then, trust is already eroding.
4. Business impact and value metrics
This is where most AI initiatives get honest with themselves. Technical performance can look great while business outcomes remain flat. Many AI projects fail because they focus on technical success metrics without creating clear accountability loops back to organizational value.
The most useful business impact metrics include:
- Revenue attribution: What incremental revenue can be credibly linked to AI-assisted decisions or workflows? This requires controlled measurement, ideally comparing cohorts with and without AI assistance.
- Cost savings from automation: Track hours saved multiplied by fully-loaded labor cost, or direct reduction in vendor spend. Be conservative. Overstatements destroy credibility.
- Customer satisfaction lift: If AI is touching customer interactions, NPS or CSAT scores before and after deployment give you a direct read on perceived quality.
- Daily active use rate: How many of the people who have access to the AI assistant are actually using it on a given day? Low daily active use is a warning sign that the tool is not delivering enough value to displace existing habits.
- Deflection rate: For AI handling support queries, sales objections, or HR requests, this measures the percentage of workflows fully resolved without human escalation. Deflection rate should only count eligible workflows and use lookback windows to avoid overstating automation benefits. Same-session deflection misses delayed escalations entirely.
- Time-to-output: How long does it take a team member to produce a deliverable with AI assistance versus without? This is one of the clearest productivity signals available.
Attributing business outcomes to AI is genuinely hard. The honest approach is to define measurement conditions before deployment, not after. Post-hoc attribution is almost always optimistic.
5. Risk and governance metrics
Ignoring risk metrics until something goes wrong is one of the most expensive mistakes an organization can make. The NIST AI Risk Management Framework is explicit: continuous monitoring is not optional. It operationalizes your governance goals into measurable practices with concrete thresholds and defined cadences.
The key risk and governance metrics to track:
- Model accuracy drift: Track weekly deviation from baseline accuracy. A drift greater than 5% per week is a standard threshold for triggering review.
- Bias disparity: Measure outcome differences across demographic subgroups per prediction batch. Disparities above 10% typically require investigation before the model continues operating.
- Compliance rate: What percentage of AI outputs meet your defined regulatory or policy requirements? For industries like finance or healthcare, this number needs to be very close to 100% continuously.
- Incident count weighted by severity: Not all AI failures are equal. A scorecard that counts incidents without weighting by impact obscures whether your risk posture is actually improving.
- Data quality score: Tracks completeness, freshness, and accuracy of inputs to your AI systems. Garbage in, garbage out is still true.
“Embedding AI risk into board-level oversight improves maturity and compliance.” — NIST AI RMF Enterprise Guide
Trust scores combining user trust, accuracy perception, and transparency give you a composite view of whether people actually rely on AI output in their decisions. A model with strong technical metrics but low trust scores is failing in practice, regardless of what the accuracy dashboard says.
6. Comparing metric categories and choosing what to prioritize
Every metric category serves a different purpose and runs on a different cadence. The table below gives you a side-by-side view.
| Category | Primary purpose | Data source | Key limitation |
|---|---|---|---|
| Model performance | Output correctness and reliability | Model logs, eval harnesses | Does not reflect business value |
| Operational health | Infrastructure efficiency and cost | System monitoring, billing APIs | Does not capture output quality |
| Business impact | Organizational value delivered | CRM, HRIS, financial reporting | Attribution is difficult |
| Risk and governance | Compliance and trust maintenance | Audit logs, bias detection tools | Requires continuous investment |
Executive AI scorecards that work well tend to cover five core dimensions: quality measured as task success rate, cost per successful completion, P95 latency, deflection rate, and incidents weighted by severity. Short scorecards enable faster decisions. Long ones get ignored.
The right prioritization depends on where you are in AI maturity. Early-stage deployments should weight model performance and operational health most heavily. You need to know the system works before you can measure whether it matters. More mature deployments should shift weight toward business impact and risk metrics, because the system’s reliability is established and the question becomes whether it is actually moving the needle.
Avoid metric sprawl. Tracking 40 AI success measurement criteria does not make your program more rigorous. It makes it unmanageable. Pick the five to eight metrics that map directly to your current strategic priorities and monitor the rest at lower frequency.
My honest take on what separates good AI measurement from theater
I have seen a lot of AI programs that look well-instrumented on paper. Dashboards full of numbers. Weekly reports going to leadership. The problem is the metrics were chosen because they were easy to collect, not because they were connected to anything the organization actually cared about.
The hardest part of evaluating AI performance is not picking the right metrics. It is getting the organization to agree on what success means before the AI goes live. Once a system is deployed, there is enormous pressure to interpret the data optimistically. Pre-commit to your targets. Define what a meaningful improvement looks like before you can see the results.
The second thing I would tell any business leader is this: do not treat risk and governance metrics as a compliance checkbox you add at the end. The cost of a bias incident or a hallucination in a customer-facing workflow is orders of magnitude higher than the cost of monitoring for it from day one. Build the measurement infrastructure as part of the deployment, not as an afterthought six months later.
Tracking task success and tool usage in production tells you something that no benchmark ever will: whether your AI actually delivers in the specific context of how your company works. That is the only question that matters in the end.
— TekkrTools
See your AI investment with full clarity
If you are managing multiple AI initiatives and trying to reconcile technical metrics with business outcomes, the measurement problem compounds fast. Tekkr’s analytics and governance platform for AI assistants gives you a single view across model performance, operational health, business impact, and risk metrics, so you are not stitching together data from five different systems.
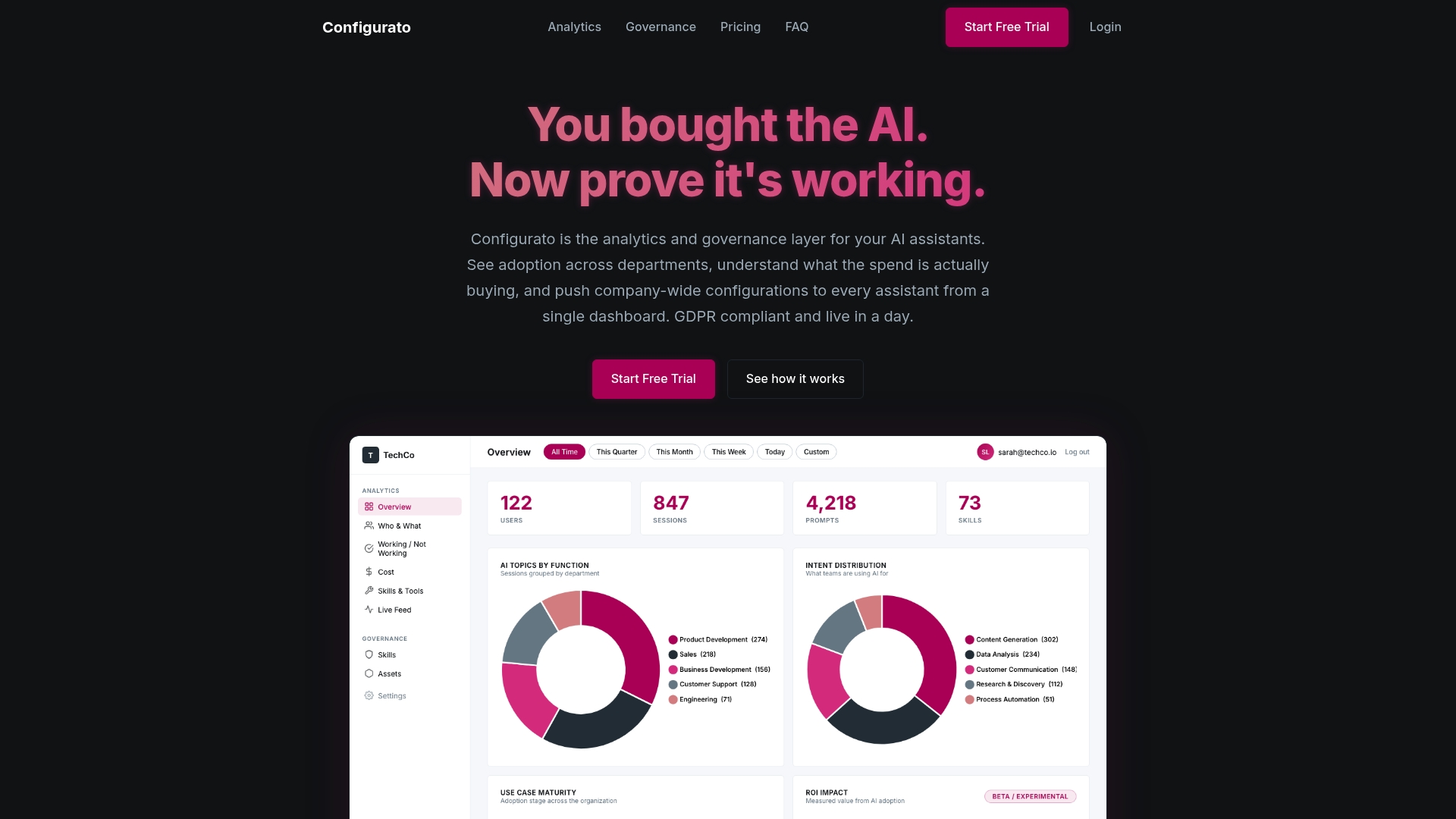
Tekkr also traces where AI is actually accelerating work and where it is not, giving you the ground truth you need to prioritize investment and close gaps. For organizations that want to understand their agentic AI ROI with credible data rather than assumptions, that visibility changes how you make decisions. Explore Configurato to see how your AI measurement program stacks up.
FAQ
What are the most important metrics for AI success?
The most important metrics span four categories: model performance (accuracy, F1, hallucination rate), operational health (P95 latency, availability, cost per successful task), business impact (adoption rate, deflection rate, cost savings), and risk governance (bias disparity, compliance rate, drift detection).
How do you measure AI effectiveness in a business context?
Measuring AI effectiveness requires connecting technical output metrics to business outcomes like revenue attribution, cost savings, and customer satisfaction. Pre-defining success targets before deployment is critical to avoiding optimistic post-hoc interpretation.
What is cost per successful task and why does it matter?
Cost per successful task divides total AI expenses including retries by the number of successfully completed tasks. It matters because token-level cost tracking hides what you actually pay for value delivered, making true economic efficiency impossible to see.
How often should you review AI success metrics?
Operational metrics like latency and availability should be monitored continuously with automated alerts. Business impact metrics warrant weekly or monthly review. Risk and compliance metrics, including bias and drift detection, require continuous automated monitoring with defined thresholds.
Why do so many AI initiatives fail to show business impact?
Most AI initiatives focus on technical metrics without creating accountability loops back to business outcomes. The fix is aligning every metric to a specific organizational goal before deployment and reviewing business impact metrics on a regular cadence with the same rigor applied to financial reporting.