
Wasted AI software spend is defined as money paid for AI tools, tokens, and subscriptions that deliver no measurable business output. Most VC-backed companies are burning 60–70% of their AI budget on redundant licenses, idle agents, and unchecked token consumption. The fix is not cutting AI investment. It is applying AI FinOps, the discipline of attributing, governing, and optimizing AI costs at the task level, to every tool in your portfolio. Companies that adopt AI FinOps practices like prompt caching, model routing, and portfolio audits cut large language model costs by 30–60% in the first year without sacrificing output quality. This guide gives you the exact framework to get there.
What do you need to reduce wasted AI software spend?
Before you can cut AI software costs, you need three things in place: visibility, accountability, and the right toolset. Without all three, any savings you find will evaporate within a quarter.
Visibility means token-level monitoring across every AI tool your organization runs. That includes OpenAI, Anthropic, Google Gemini, and any internal models. You cannot govern what you cannot see. Most finance teams are working from monthly invoice totals, which is far too coarse to catch waste at the source.

Accountability means replacing the old headcount-based cost model with a new one. Traditional finance models built around seat counts and fixed licenses do not map to AI’s consumption-based pricing. You need cost attribution down to the team and feature level, so every dollar of AI spend has an owner.
Toolset means having the infrastructure to act on what you see. The core AI FinOps toolkit includes:
- Cost attribution systems that tag spend by team, project, and use case
- Prompt caching infrastructure to avoid re-processing identical or near-identical inputs
- Model routing layers that direct requests to the cheapest capable model automatically
- Real-time anomaly detection to catch runaway agents or unexpected usage spikes before they hit your invoice
Pro Tip: Start with a cross-functional FinOps team that includes at least one representative from finance, engineering, and procurement. Siloed ownership is the single biggest reason AI cost controls fail.
The organizational prerequisite that most companies skip is formal spend ownership. Someone must be accountable for the AI budget the same way a VP of Engineering owns headcount. Without that person, every cost-saving initiative dies in committee.

How to audit your AI portfolio and cut redundant subscriptions
An AI software audit is a structured review of every tool, license, and API contract your organization pays for, mapped against actual usage data. It is the fastest way to find money you are already wasting.
Run the audit in four steps:
- Collect the data. Pull invoices, API billing dashboards, and SaaS contract records for the past 90 days. Include shadow IT by surveying department heads directly.
- Group tools by function. Cluster your AI tools into categories: code generation, writing assistance, data analysis, customer support, and so on. You will almost certainly find three or four tools doing the same job.
- Score each tool on usage and output. Flag any tool where fewer than 40% of licensed seats are active. 53% of enterprise SaaS licenses are unused or underused. That number is almost certainly worse in AI, where tools get purchased on hype and forgotten.
- Build a decommission plan. For every redundant tool, assign a sunset date, a migration path, and an owner. Decommissioning without a migration plan creates productivity gaps that kill adoption of the tools you keep.
Pro Tip: When consolidating tools, negotiate volume discounts with your surviving vendors before you cancel the redundant ones. Your increased commitment to a single vendor is leverage. Use it.
The comparison below shows how the audit output typically looks before and after rationalization:
| Category | Before Audit | After Rationalization |
|---|---|---|
| Code generation tools | 4 active subscriptions | 1 primary, 1 backup |
| Writing assistance | 3 overlapping tools | 1 consolidated license |
| Data analysis AI | 2 tools with 30% usage each | 1 tool at 75% usage |
| Monthly spend | ~$120 per team member | ~$50–70 per team member |
Quarterly AI asset rationalization is not optional. The AI tool market moves fast enough that a tool you evaluated six months ago may already have a cheaper or better alternative. Set a recurring calendar event and treat it like a board-level budget review.
What technical optimizations cut token costs without hurting quality?
Token spend is where the largest savings live, and most engineering teams are leaving serious money on the table. The four levers below are ranked by typical impact.
Prompt caching is the highest-ROI lever available. When your application sends the same system prompt or context block repeatedly, caching stores that input so the model does not reprocess it. Prompt caching cuts input token costs by 80–90% on high-reuse workloads. Anthropic’s Claude and OpenAI both support prompt caching natively. If you are not using it, you are paying full price for work the model has already done.
Model routing is the practice of directing each request to the cheapest model capable of handling it well. A customer support FAQ query does not need GPT-4o. A lightweight model handles it at a fraction of the cost. The key insight here is that optimizing for total task completion cost, not per-token price, is what actually saves money. A cheap model that fails and retries three times costs more than a capable model that succeeds on the first call.
Batch processing applies to any workload that is not time-sensitive. Async batch API calls for non-real-time tasks cut token costs by 50% with no quality loss. Document summarization, data enrichment, and report generation are all strong candidates for batching.
Context compression means trimming unnecessary tokens from your prompts before they reach the model. Audit your longest prompts for redundant instructions, repeated context, and verbose formatting. Cutting 30% of input tokens from a high-volume workflow compounds into significant savings over a month.
For a practical framework on getting more from the tools you keep, Tekkr’s guide on AI output strategies covers how to structure prompts and workflows for maximum return.
What are the most common pitfalls that cause runaway AI costs?
The most expensive mistake in AI spend management is not overpaying for a subscription. It is an unchecked agentic loop. Runtime agentic loops occur when an AI agent continuously re-prompts itself without a termination condition. A single misconfigured agent can consume thousands of dollars in tokens overnight. The fix is mandatory per-run budget caps with automatic termination, not monthly budget reviews that catch the damage weeks later.
Three other pitfalls show up repeatedly in VC-backed companies:
- Additive budgeting. New AI tools get approved without retiring old ones. Spend grows every quarter without a corresponding growth in output. The solution is subtractive budgeting, where every new AI tool approval requires identifying a legacy tool to decommission.
- Manual model selection. When developers choose models manually, they default to the most capable and most expensive option. Automated routing logic that is invisible to the developer enforces cheaper model usage when the task allows it. One engineering team using this approach cut their AI coding bill by 65% without changing their output quality.
- Shadow AI spend. Department heads buy AI tools on corporate cards and expense them as software. Finance never sees it until the annual audit. Require all AI tool purchases to route through a central procurement process, no exceptions.
The companies that control AI spend long-term are not the ones with the strictest budgets. They are the ones with the best real-time visibility. A $10,000 anomaly caught on day one costs nothing to fix. Caught on day 30, it is already in the invoice.
Which metrics and governance practices keep AI costs under control?
Sustainable cost control requires metrics that connect spend to output, not just to usage. The three metrics that matter most are:
- Cost per successful output. This is the unit economics of your AI investment. Divide total AI spend by the number of completed, accepted outputs (reports generated, tickets resolved, code merged). Track this monthly by team.
- Cost attribution by team and feature. LLM FinOps requires granular attribution down to the team and feature level. Without it, you cannot identify which part of the business is driving cost growth.
- Cache hit rate. This metric tells you how effectively your prompt caching infrastructure is working. A cache hit rate below 60% on high-reuse workloads signals a configuration problem worth fixing immediately.
On the governance side, set negotiated caps and tiered pricing in every AI vendor contract. Most vendors will agree to volume-based pricing if you commit to a minimum spend. Lock those rates in before your usage grows, not after.
Pro Tip: Run a quarterly AI governance review with finance, engineering, and at least one business unit leader. The goal is not just to review spend. It is to surface use cases that are working and double down on them, while cutting the ones that are not.
Real-time anomaly detection embedded in your operational workflows is the difference between reactive and proactive cost management. Set alerts for any team or feature that exceeds 120% of its baseline daily spend. Investigate before the billing cycle closes.
For executives building their broader AI governance framework, Tekkr’s resource on enterprise AI adoption covers the organizational structures that make cost discipline stick.
Key takeaways
Reducing wasted AI software spend requires systematic auditing, technical optimization through AI FinOps practices, and a governance model that attributes costs to outputs rather than headcount.
| Point | Details |
|---|---|
| Audit first, cut second | Map every AI tool by function and usage before canceling anything to avoid productivity gaps. |
| Prompt caching is the top lever | Enabling caching on high-reuse workloads cuts input token costs by 80–90% with no quality loss. |
| Subtractive budgeting controls growth | Every new AI tool approval must be offset by retiring a legacy tool to prevent additive spend creep. |
| Govern with output metrics | Track cost per successful output and cache hit rate, not just total spend, to connect cost to value. |
| Quarterly rationalization is mandatory | AI tool markets evolve fast enough that a six-month-old portfolio decision may already be costing you money. |
The uncomfortable truth about AI spend management
Most finance leaders I work with assume their AI spend problem is a procurement problem. Buy fewer tools, negotiate harder, done. That framing is wrong, and it leads to the wrong solutions.
The real problem is that AI costs are dynamic in a way that SaaS costs never were. A SaaS license costs the same whether you use it or not. An AI agent costs nothing when idle and thousands of dollars per hour when misconfigured. Traditional finance models were not built for that volatility.
What I have seen work is treating AI spend governance as an engineering problem that finance owns. The controls that actually prevent runaway costs, per-task budget caps, automated routing, real-time anomaly detection, live in the codebase. Finance leaders who wait for monthly invoices to catch problems are always fighting last month’s fire.
The other shift that matters is moving from cost minimization to value maximization. The goal is not the lowest possible AI bill. It is the best cost per successful output. I have seen companies cut their AI spend by 40% and watch productivity drop because they cut the wrong tools. The metric that keeps you honest is output, not spend.
The executives who will win this are the ones building cross-functional accountability now, before their AI budgets triple. That means finance, engineering, and business unit leaders sharing a single dashboard, a single set of metrics, and a single quarterly review. That structure does not happen organically. Someone has to build it deliberately.
— TekkrTools
See exactly where your AI budget is going
If you have read this far, you already know the problem. The harder part is getting the visibility to act on it. Tekkr’s platform, Configurato, tracks AI adoption and spend across your entire organization, breaks costs down by team and tool, and surfaces which use cases are actually delivering return.
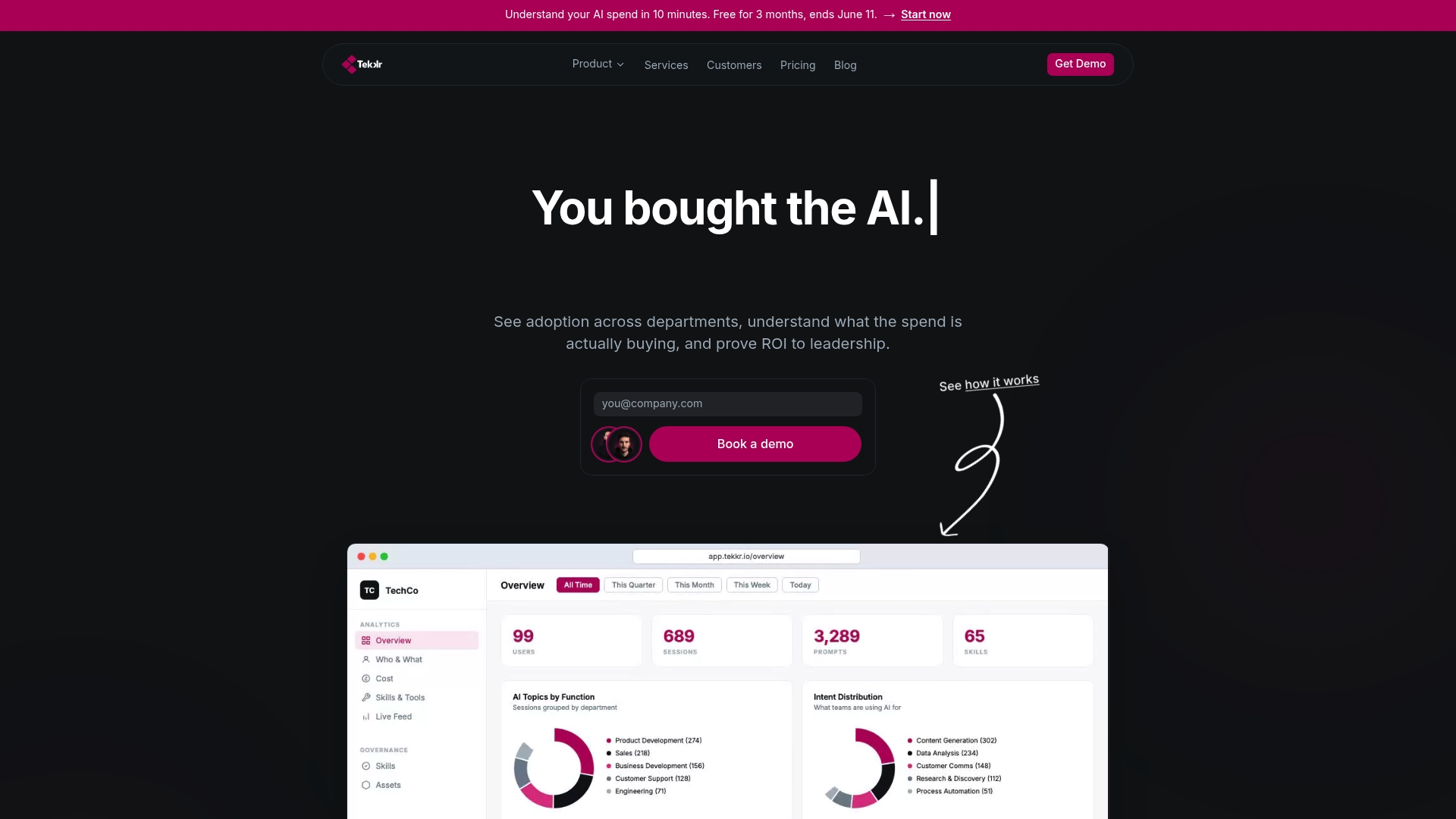
Tekkr works with VC-backed enterprises to turn AI investments into measurable results. Configurato identifies idle licenses, flags cost anomalies in real time, and gives your finance and engineering teams a shared view of what is working. Setup takes 10 minutes, there is a free tier, and no credit card is required. Explore Tekkr’s AI adoption solutions or go deeper with the Configurato product to see how cost visibility and adoption management work together.
FAQ
What is AI FinOps and why does it matter for executives?
AI FinOps is the practice of attributing, governing, and optimizing AI costs at the task and team level. It replaces headcount-based budget models with consumption-based controls that match how AI tools are actually priced.
How much can prompt caching reduce AI token costs?
Prompt caching cuts input token costs by 80–90% on high-reuse workloads. Both Anthropic and OpenAI support it natively, making it one of the fastest wins available for companies running high-volume AI workflows.
What is the best way to minimize AI spending on subscriptions?
Conduct a quarterly audit that groups tools by function, scores each on active usage, and decommissions any tool where fewer than 40% of licenses are actively used. Systematic audits typically save $40–80 per team member per month.
How do agentic loops cause runaway AI costs?
Agentic loops occur when an AI agent re-prompts itself continuously without a termination condition, consuming tokens at an unchecked rate. The fix is mandatory per-run budget caps with automatic termination built into the agent’s configuration.
Which metric best measures AI software ROI?
Cost per successful output is the most reliable metric. It divides total AI spend by completed, accepted outputs and connects your budget directly to business value rather than raw usage volume.