
Most teams assume AI quality is a checklist you run once before deployment. It isn’t. When you define AI quality standards, you are committing to a living system of definitions, measurements, and continuous checks that spans your data pipelines, model behavior, and final outputs. Get this wrong and you end up with AI that looks functional in a demo but fails unpredictably in production. Get it right and you build the kind of organizational trust in AI that actually compounds over time.
Table of Contents
- Key Takeaways
- Recognized AI quality standards and frameworks
- The three pillars of AI quality
- Why AI QA is different from traditional software testing
- How to implement AI quality standards in practice
- My perspective on AI quality standards
- Operationalize your AI quality standards with Tekkr
- FAQ
Key Takeaways
| Point | Details |
|---|---|
| Quality is a spectrum, not a switch | AI quality exists across multiple dimensions that require separate definitions and metrics. |
| Established frameworks exist | Standards like ASQI, HATS v1.0, and ISO/IEC 42001 give organizations proven starting points. |
| Three pillars must all hold | Data quality, model quality, and output quality each need dedicated measurement protocols. |
| AI QA is probabilistic | Traditional pass/fail testing does not apply to AI systems; continuous monitoring is the only defensible approach. |
| Governance alignment is non-negotiable | Quality standards must connect to your regulatory and ethical compliance requirements from day one. |
Recognized AI quality standards and frameworks
Before you can define AI quality standards for your own organization, you need to understand the frameworks others have already built and validated. These are not academic exercises. They are structured tools that address real governance, risk, and compliance needs.
The Resaro ASQI (AI Solutions Quality Index) is one of the more practical multi-level approaches available. It uses five levels of quality indicators, each tailored to specific AI use cases. The structure is detailed enough to be meaningful but practical enough for real-world decision-making. Think of it as a graduated rubric that lets you score AI systems without collapsing everything into a vague “good” or “bad” verdict.
HATS v1.0 takes a fundamentally different angle. Rather than focusing on model accuracy, it defines a three-tiered certification framework built around governance proof, data separation, and audit permanence. Certification is continuous and cryptographically verifiable, which means trustworthiness is not a one-time declaration but an ongoing, provable state. For organizations operating in regulated industries, this distinction matters enormously.
Then there is ISO/IEC 42001, which Oracle describes as internationally recognized for institutionalizing AI governance across complex organizations. It covers the full AI management lifecycle: risk, compliance, and governance together. A companion standard, ISO/IEC 25059, extends traditional software quality metrics specifically to AI systems.
Here is how these frameworks compare across key dimensions:
| Framework | Focus area | Certification type | Best suited for |
|---|---|---|---|
| Resaro ASQI | Use-case-specific quality scoring | Index-based | AI product teams |
| HATS v1.0 | Governance and data trust | Continuous, cryptographic | Regulated industries |
| ISO/IEC 42001 | AI management system | International standard | Enterprise governance |
| ISO/IEC 25059 | AI-specific software quality | Standard metrics | Engineering teams |
No single framework covers everything. Most mature organizations layer two or three of these together, using ASQI for product-level scoring, HATS or ISO/IEC 42001 for governance accountability, and ISO/IEC 25059 for technical benchmarking.
The three pillars of AI quality
When organizations try to define quality standards for AI, they often focus narrowly on model performance and miss the two other dimensions that determine whether the system actually works in practice. AI quality has three distinct pillars, and all three must hold.

Data quality
Data quality is where most AI projects quietly fail. The issues are rarely obvious at the start. Poor data representativeness and undiscovered bias tend to surface only after deployment, when the cost of fixing them is highest. Neglecting data quality standards early leads to expensive technical debt and model pipeline rework. The dimensions to measure here include accuracy, completeness, consistency, and auditability. You also need documented bias mitigation processes before training begins, not after.
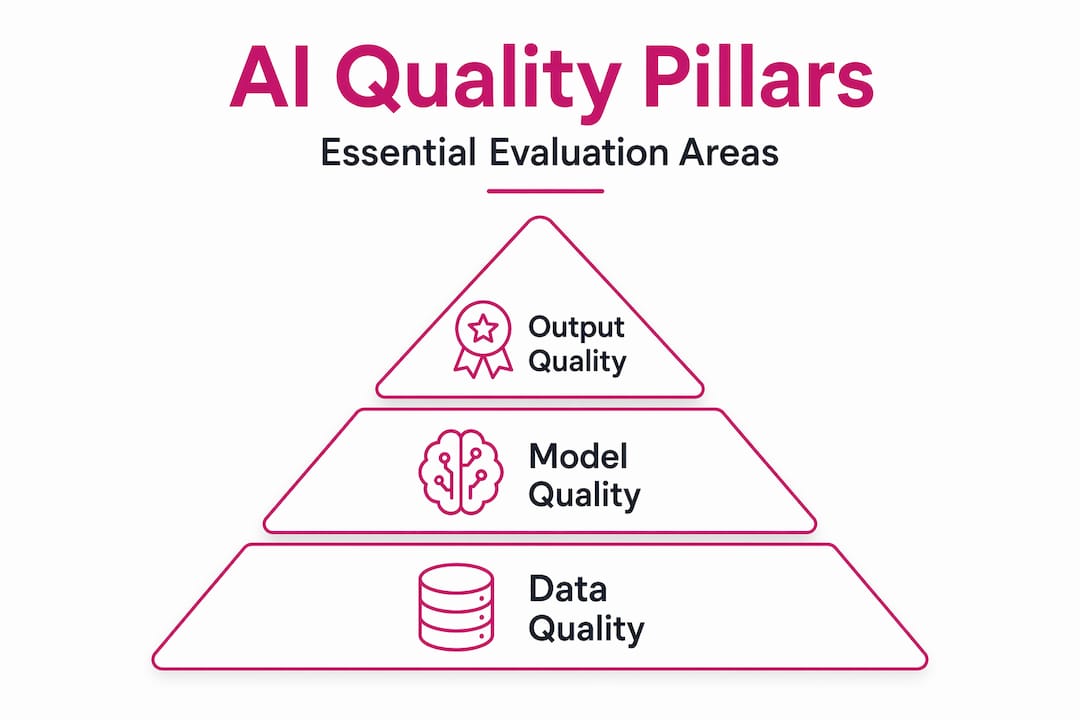
Model quality
Model quality covers how well the system performs against defined objectives. This includes standard metrics like accuracy, precision, and recall, but also harder-to-measure properties like robustness under distribution shift, fairness across demographic groups, and explainability. An AI model that performs well on your test set but cannot explain its decisions is not a quality system. It is a liability waiting to be discovered.
Output quality
This is where the work becomes visible to end users, and it is the most underspecified pillar in most organizations. Evaluating AI outputs requires checking safety, tone, relevance, coherence, and factual accuracy, especially in generative AI contexts. One practical approach is a structured scoring rubric. A 12-point scoring system that requires 84 or more points for approval, for example, removes the subjectivity that makes output quality reviews inconsistent across teams.
Pro Tip: Set output quality thresholds before you launch, not after you receive complaints. A defined floor score, reviewed and calibrated quarterly, does more for consistency than any amount of ad hoc review.
- Define data quality criteria and bias checks before model training begins.
- Establish model performance baselines tied to business outcomes, not just technical benchmarks.
- Create a structured output evaluation rubric with documented pass thresholds.
- Assign clear ownership for each pillar across your data, ML, and product teams.
- Schedule quarterly calibration reviews to update thresholds as your use cases evolve.
Why AI QA is different from traditional software testing
If you have ever run a traditional QA process, you understand the appeal of binary outcomes. A test either passes or fails. A build ships or it does not. AI quality assurance does not work that way, and organizations that apply traditional testing logic to AI systems end up with false confidence and real failures.
AI quality assurance is probabilistic, not deterministic. The core challenges are data bias, model drift, and statistical performance degradation, none of which show up cleanly in a pass/fail test matrix. A model that was accurate six months ago may have quietly drifted as the data distribution it operates on has shifted. You would not know unless you were continuously watching the right signals.
Here is how the two approaches compare across key quality metrics:
| Dimension | Traditional software QA | AI quality assurance |
|---|---|---|
| Test outcome | Deterministic pass/fail | Probabilistic score ranges |
| Failure mode | Explicit errors, crashes | Bias, drift, degradation |
| Monitoring need | Point-in-time testing | Continuous monitoring |
| Key metrics | Bug counts, test coverage | Accuracy, precision, bias metrics, drift rates |
| Primary risk | Functional defects | Silent performance decay |
The implication for your organization is significant. You need monitoring infrastructure, not just test suites. AI-powered automated quality assurance can review 100% of AI interactions in real time, which eliminates the sampling bias that makes periodic manual reviews unreliable. Reviewing 5% of outputs on a weekly basis tells you very little about what the system is actually producing.
Pro Tip: Treat model drift detection as a first-class engineering concern. Set automated alerts for statistical deviation from your baseline performance metrics, and define in advance what deviation threshold triggers a review versus a rollback.
Applying AI-driven evaluation methods also allows organizations to maintain longer and more precise quality policy specifications than any manual review process can realistically sustain. The organizations winning at AI quality right now are not doing more manual review. They are building systems that make continuous quality enforcement automatic.
How to implement AI quality standards in practice
Knowing the frameworks is not enough. You need a sequenced approach that connects organizational goals to measurable quality definitions and embeds those definitions into your actual AI workflows.
-
Start with your use cases, not the frameworks. Audit the AI applications you currently run or plan to run. Map each one to the business outcome it is supposed to drive. Your quality definitions should flow from those outcomes, not from a generic framework adopted wholesale.
-
Choose a primary framework and adapt it. If you operate in a regulated industry, HATS v1.0 or ISO/IEC 42001 gives you the governance accountability you need. If you are building AI products and need to score quality across diverse use cases, combining standardized indices with tailored use-case specifics gives you a practical balance. Do not try to implement every framework at once.
-
Run a data quality pilot before full model development. Before any significant model work begins, audit a representative sample of your training and inference data against your defined quality criteria. Issues caught here cost a fraction of what they cost post-deployment.
-
Define model validation protocols with business stakeholders, not just ML engineers. Your validation criteria should include technical metrics and business-relevant indicators. A model that is 94% accurate on a test set but makes systematically worse predictions for a key customer segment is not a quality model by most business definitions.
-
Build continuous monitoring into your deployment architecture from the start. Set baseline performance metrics at launch. Define the deviation thresholds that trigger review cycles. Assign a team responsible for ongoing recalibration. This is not a one-time setup. It is an operational discipline.
-
Align every quality standard with your regulatory and ethical compliance requirements. AI quality and AI compliance are not separate conversations. Document how your quality standards satisfy applicable regulations, and review that documentation every time regulations or use cases change.
What is an AI quality gate in this context? A quality gate is a defined checkpoint in your AI development or deployment pipeline where output must meet a specified threshold before moving to the next stage. Quality gates operationalize your standards. Without them, standards remain aspirational documents rather than enforced practice.
My perspective on AI quality standards
I have watched organizations spend months selecting frameworks and almost no time actually enforcing them. The frameworks are not the hard part. Enforcement is.
The most common mistake I see is treating data quality as a pre-training concern that gets addressed once and then closed. Data drifts. The world changes. What was a clean, representative dataset at training time becomes a liability eighteen months into production. The organizations that catch this early are the ones that built monitoring into their culture, not just their tooling.
My other observation is that quality standards without assigned ownership are theater. You can write the most detailed quality rubric in your industry, but if no one has a quarterly obligation to recalibrate it, it will be out of date within a year. The role of quality assurance in AI is not a project. It is a function, and it needs to be treated like one.
If I could give one piece of advice to any AI leader reading this: define your quality gates before you define your launch timeline. Every time I have seen the reverse happen, the quality standards become whatever the system already produces. That is not a standard. That is a rationalization.
— TekkrTools
Operationalize your AI quality standards with Tekkr
You have the frameworks. You have the pillars. Now comes the part most organizations underestimate: embedding those standards into daily AI work so they actually get enforced.
Tekkr’s Configurato platform was built for exactly this gap. It codifies your organization’s quality standards, processes, and governance requirements directly into the AI assistants your teams already use. Whether you are enforcing output quality thresholds, tracking model performance signals, or maintaining compliance with ISO/IEC 42001 requirements, Configurato makes your standards operational rather than aspirational. Your people do not change how they work. Your AI simply starts producing output that already meets your bar.
FAQ
What does it mean to define AI quality standards?
Defining AI quality standards means establishing measurable criteria across data quality, model performance, and output evaluation that AI systems must meet before and during deployment. These standards connect technical benchmarks to business outcomes and compliance requirements.
What is AI quality assurance?
AI quality assurance is the practice of continuously monitoring and validating AI system performance across probabilistic metrics like bias, drift, and output accuracy, rather than relying on traditional pass/fail software testing.
What are examples of AI quality standards?
Examples include the Resaro ASQI five-level quality index, HATS v1.0 cryptographic certification, ISO/IEC 42001 governance requirements, and structured output scoring rubrics that require minimum threshold scores before AI content is approved.
What is an AI quality gate?
An AI quality gate is a defined checkpoint in an AI development or deployment pipeline where output must meet a specified performance or safety threshold before proceeding to the next stage or reaching end users.
How does AI quality assurance differ from traditional software QA?
Traditional software QA uses deterministic pass/fail tests. AI quality assurance is probabilistic, requiring continuous monitoring of statistical performance metrics, bias indicators, and model drift rather than binary correctness checks.