
Most organizations treat cross-company AI data sharing as a problem for later. Too risky, too complex, too many unknowns. That instinct is costing them real competitive ground. Explaining cross-company AI data clearly, without the fog of vendor jargon, is one of the most strategically useful things an executive or data analyst can do right now. The organizations that figure out how to share AI-relevant data across company boundaries, securely and deliberately, are the ones that will accelerate faster than their more isolated peers. This article gives you the frameworks, technologies, and governance thinking to make that happen.
Table of Contents
- Key takeaways
- Explaining cross-company AI data: scope, types, and benefits
- Technologies that enable secure AI data collaboration
- Governance, compliance, and risk management
- Implementing cross-company AI data strategies
- Challenges and future trends
- My honest take after watching organizations attempt this
- How Tekkr helps you govern AI across organizational boundaries
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Cross-company AI data is a strategic asset | Sharing AI-relevant data across organizations unlocks efficiency gains and innovation not achievable in isolation. |
| Governance must come first | Regulatory compliance, data ownership policies, and audit trails need to be established before any data sharing begins. |
| Technology enables secure collaboration | Sanitization layers, multi-tenant workspaces, and ISO 27001 certified platforms make sharing technically feasible without exposing sensitive data. |
| Cross-functional committees drive adoption | Combining IT, finance, HR, and operations in AI governance decisions produces measurably better outcomes. |
| Start with a pilot, then scale | A phased approach, beginning with a controlled pilot, reduces risk and builds organizational confidence before full deployment. |
Explaining cross-company AI data: scope, types, and benefits
Cross-company AI data refers to any data, models, telemetry, or learned patterns that flow between two or more organizations to improve AI performance, decision-making, or workflow outcomes. It is not simply sending a spreadsheet to a partner. It includes training datasets shared under data collaboration agreements, AI model outputs exchanged to validate predictions across organizations, behavioral telemetry pooled to improve AI agent performance, and anonymized workflow patterns benchmarked across companies.
The strategic case is straightforward. No single company has complete data on any complex problem. Supply chain disruptions, fraud patterns, clinical outcomes, and product quality signals all exist across organizational boundaries. When you keep AI learning inside your own walls, you are training on a partial picture.

Here is how isolated AI data compares to cross-company AI collaboration:
| Dimension | Isolated AI data | Cross-company AI collaboration |
|---|---|---|
| Training data breadth | Limited to internal datasets | Pooled across partners for richer signals |
| Pattern recognition accuracy | Constrained by organizational blind spots | Improved by exposure to diverse data sources |
| Speed of AI improvement | Slow, dependent on internal volume | Faster due to shared learning |
| Compliance complexity | Simpler internally | Requires active governance frameworks |
| Competitive differentiation | Preserved but limited | Shared risk, shared upside in partnership models |
Common scenarios where organizations already leverage cross-company AI data include automotive supply chains where manufacturers share quality telemetry with Tier 1 suppliers, financial services partnerships where fraud signals are pooled across institutions, and healthcare networks where de-identified patient outcome data trains diagnostic models. These are not edge cases. They are where the most mature AI programs operate today.
Technologies that enable secure AI data collaboration
The technology infrastructure behind cross-company AI collaboration has matured significantly in the past two years. You do not need to build custom solutions from scratch. You need to understand which categories of tooling are non-negotiable.
The core components that make this work:
-
Multi-tenant virtual workspaces: These are governed environments where multiple organizations can work with shared AI pipelines without their raw data ever touching each other’s systems. Multi-tenant virtual workspaces unify data preparation, training, validation, and deployment in a single secure environment. Toyota’s Woven by Toyota initiative uses exactly this model to enable cross-company software and AI development at scale.
-
Programmable data sanitization layers: Think of this as a filter that sits between your systems and the AI model. A sanitization proxy can deploy within 30 days without disrupting existing systems, handling detection, tokenization, policy enforcement, logging, and threat protection simultaneously.
-
Agent telemetry sharing protocols: One of the more underappreciated advances is the ability to share what AI agents learned without sharing the underlying customer data. Safe telemetry sharing accelerates cross-company AI debugging and collective improvement while keeping sensitive information inside its originating boundary.
-
ISO 27001 certified synchronization platforms: For audit and compliance credibility, ISO 27001 certified tools are increasingly becoming the standard for governing AI integrations across company lines.
When you are selecting vendors, the two questions that matter most are whether they support pseudonymization natively and whether they provide auditable logs of every data access event. Any vendor that cannot answer both clearly is not ready for enterprise cross-company deployment.
Pro Tip: Before evaluating any platform, map the data flows you intend to share and classify each by sensitivity. Vendors should be selected against your specific flow map, not against generic feature checklists.
For a practical reference on secure AI agent workflows, the step-by-step breakdown covers the sequencing of authentication, encryption, and policy enforcement that most enterprise pilots skip over initially.
Governance, compliance, and risk management
Technology without governance is just exposure at scale. This is where most cross-company AI pilots fail. They solve the engineering problem and ignore the policy problem until something goes wrong.
The regulatory landscape is genuinely complex. Here is the layered compliance challenge you are managing:
-
GDPR (European Union): Requires a legal basis for data processing, mandates data minimization, and restricts transfers outside the EU. AI data pipelines crossing European organizational boundaries must meet these requirements before the first byte moves.
-
HIPAA (United States): Any cross-company AI collaboration involving health information requires Business Associate Agreements and strict access controls. The sanctions for violations are not just financial. They are reputational.
-
KVKK (Turkey): Similar in structure to GDPR but with distinct local requirements around explicit consent and data residency. Organizations with Turkish partners often underestimate this one.
-
IP and data ownership: Whose model is it when two companies train jointly? Who owns the insights produced by shared data? These questions need written agreements, not assumptions.
Data pseudonymization, when implemented at the sanitization layer level, functions as a technical control under GDPR, KVKK, and HIPAA simultaneously, reducing the compliance surface area for cross-border AI workflows significantly.
Pseudonymization at the sanitization layer is the most practical tool you have for satisfying multiple regulatory frameworks without building separate compliance pipelines for each jurisdiction.
Policy engines and audit trails are equally non-negotiable. Every AI workflow in a cross-company context should produce a tamper-proof log of what data was accessed, by which system, at what time, and under which policy rule. This is not just for regulators. It is for your own operational trust.
Pro Tip: Stand up a cross-functional AI governance committee before you launch any pilot. Include legal, IT, finance, and at least one business unit leader. The decisions they make in the first 30 days will shape your entire governance structure.
Implementing cross-company AI data strategies
You can have the right technology and a solid governance framework and still fail at implementation. The execution gap is almost always organizational, not technical.
Here is what a phased approach looks like in practice:
-
Phase 1, Pilot: Select one partner and one data type with low sensitivity. Define the use case precisely. Deploy your sanitization layer, set up the governance committee, and run for 60 to 90 days with active monitoring.
-
Phase 2, Feedback and iteration: Collect structured feedback from every stakeholder group: IT on system performance, legal on compliance gaps, business units on output quality. Do not skip this step to move faster. The feedback surfaces problems that will compound at scale.
-
Phase 3, Expansion: Add partners and data types incrementally. Each addition should go through the same governance checkpoint as the original pilot. Shortcuts here create technical debt in your compliance posture.
-
Phase 4, Scaling: Formalize the operating model, establish SLAs with partners, and automate policy enforcement wherever possible.
Cross-functional collaboration across IT, finance, HR, and operations in AI initiatives produces over 30% efficiency gains and 25% waste reduction compared to siloed implementations. That is not a marginal difference. It is the difference between a successful program and one that gets defunded after 18 months.
Pro Tip: Measure outcomes from day one of your pilot. Define two or three specific metrics before you start, such as time saved, decision accuracy, or error rate reduction. Without baseline measurements, you cannot demonstrate value when budget reviews arrive.
Change management is often the last thing organizations plan and the first thing that kills adoption. Employees at partner organizations need to understand why data is being shared and what protections are in place. Transparency here is not optional. PwC’s approach to scaling AI, which involved training 30,000 professionals on how to use AI models effectively, demonstrates that investment in human readiness is as important as technical infrastructure.
Challenges and future trends
Even well-resourced organizations run into consistent friction points in cross-company AI collaboration. Knowing them in advance lets you plan around them rather than discover them mid-pilot.
| Challenge | Current reality | Emerging solution |
|---|---|---|
| Single-tenant trust models | Most AI systems are not designed to share telemetry across boundaries | Privacy-safe telemetry sharing profiles |
| Contractual complexity | Data sharing agreements take 3 to 6 months to negotiate | Standardized AI data partnership templates |
| Siloed infrastructure | Legacy systems cannot connect to multi-tenant environments | Cloud-native migration as prerequisite |
| IP ownership disputes | Joint training creates ambiguous ownership | Pre-negotiated model ownership clauses |
Looking forward, the internet itself is adapting to AI data consumption. Machine-readable AI data permissions through standards like XML sitemaps and LLMs.txt are moving toward a negotiated web model that balances openness with IP protection. This will eventually shape how organizations define what AI systems can and cannot access from their external-facing data.
For multi-cloud AI data exchange, the architectural patterns that organizations are adopting now will determine how easily they can plug into these emerging standards as they mature.
My honest take after watching organizations attempt this
I have watched organizations approach cross-company AI collaboration in two ways. The first group treats it as a technical initiative and hands it to engineering. The second group treats it as a strategic initiative with a technical component. The first group consistently runs into walls around month four. The second group actually ships something.
The most common mistake is underestimating how much of this is a people and policy problem, not a platform problem. I have seen organizations with genuinely excellent data infrastructure fail because no one owned the governance question, and the partnership stalled when a legal team asked a question that nobody could answer.
The flip side is that organizations often miss quick wins by waiting for the perfect governance structure before starting. You do not need everything resolved on day one. You need enough resolved to run a controlled pilot safely.
The organizations I have seen succeed shared one characteristic: they appointed someone with enough organizational authority to convene the right stakeholders and make binding decisions about governance. Not a committee. One person with a mandate and a committee behind them.
Compliance and speed are not opposites in this space. A well-structured sanitization layer and a clear policy engine let you move fast within defined boundaries. The boundaries themselves are the competitive advantage.
— TekkrTools
How Tekkr helps you govern AI across organizational boundaries
If you are at the stage where cross-company AI collaboration is moving from concept to initiative, the governance and configuration layer is where most programs need the most support.
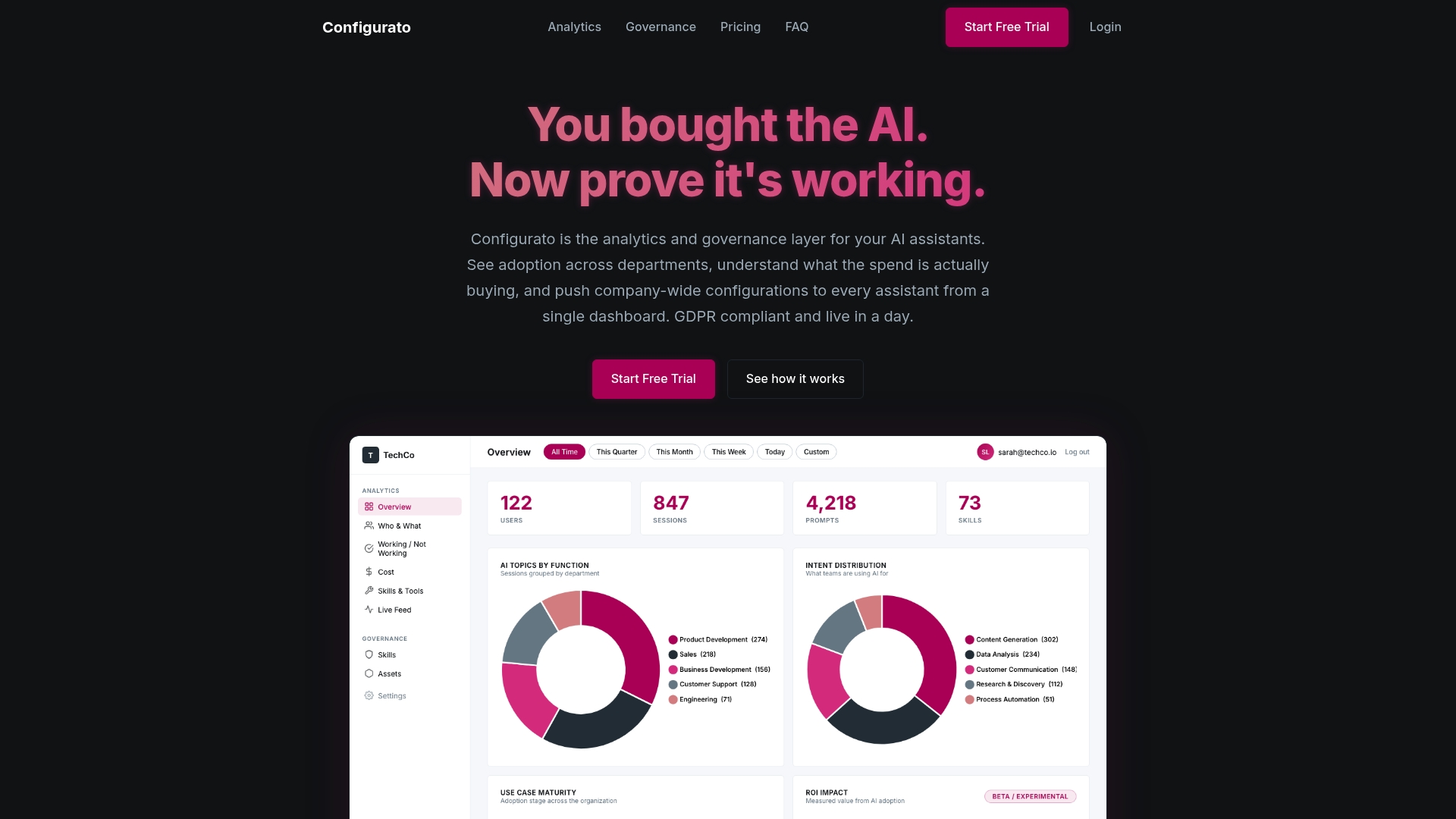
Tekkr’s Configurato platform is built specifically for organizations that need visibility into how AI assistants are performing and what they are doing with company data. It embeds your governance standards, quality controls, and workflow policies directly into AI assistant behavior, across Claude, GPT, Copilot, and Gemini, without requiring employees to change how they work. For teams exploring cross-company AI data strategies, the benchmarking layer in Configurato provides cross-company pattern data that shows what high-performing AI adoption actually looks like at an organizational level. It is the governance and analytics layer that makes AI collaboration visible, auditable, and improvable over time.
FAQ
What is cross-company AI data sharing?
Cross-company AI data sharing involves the secure exchange of datasets, AI model outputs, or behavioral telemetry between two or more organizations to improve AI performance and collaboration. It requires formal governance agreements and technical controls like data sanitization to operate safely.
How do organizations keep data private when sharing AI data?
Pseudonymization and programmable sanitization layers strip or encrypt identifying information before data crosses organizational boundaries. These controls can satisfy GDPR, HIPAA, and KVKK requirements simultaneously when implemented correctly at the infrastructure level.
What regulations apply to cross-company AI data sharing?
GDPR applies to EU-based data, HIPAA governs US health data, and KVKK applies in Turkey. Each requires specific controls around consent, data residency, and access management, which is why a legal review should precede any cross-company AI data pilot.
How long does it take to set up a cross-company AI data program?
A controlled pilot with one partner can be operational in 60 to 90 days if governance agreements are in place and the technical sanitization layer is deployed early. Full scaling across multiple partners typically takes 12 to 18 months.
What is the biggest reason cross-company AI data initiatives fail?
Most failures come down to governance gaps rather than technical problems. Organizations that do not establish clear data ownership, policy enforcement, and cross-functional accountability before launching pilots consistently struggle to scale or sustain their programs.