
Every CTO has heard the promise: AI will transform your engineering output. Yet most organizations that roll out AI coding tools find themselves six months later with high adoption dashboards, underwhelming productivity numbers, and engineers who aren’t sure whether they’re faster or just differently busy. The gap between AI hype and realized value is real, and it’s closing companies’ competitive windows faster than they realize. Cloudflare’s internal AI engineering stack achieved 93% adoption across its R&D organization, with merged requests climbing from 5,600 to 8,700 per week, but that result came from disciplined strategy, not tool deployment alone.
Table of Contents
- Define your success criteria before adopting AI
- Select and integrate the right AI engineering stack
- Overhaul engineering processes to avoid new bottlenecks
- Mitigate AI-specific risks: memory, statelessness, and edge cases
- Why AI-driven engineering isn’t just about acceleration—it’s rethinking the operating model
- Enable measurable AI impact with enterprise analytics and governance
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Set clear AI goals | Always define success by business-aligned KPIs before implementing new AI tools. |
| Pick the right stack | Choose your AI engineering stack on adoption history and alignment with your processes. |
| Revamp your processes | AI alone won’t remove bottlenecks—real impact comes from redesigning the workflow. |
| Address AI project risks | Mitigate issues around memory, context, and edge-cases in long or complex projects. |
| Redesign your operating model | Transform roles and structures to unlock true AI-driven engineering value long-term. |
Define your success criteria before adopting AI
With the strategic context set, let’s explore how to anchor AI-driven engineering to real business goals.
Most AI engineering initiatives fail not because the technology underperforms, but because success was never clearly defined. Before you authorize a single seat license or spin up a pilot, you need to know exactly what “better” looks like in measurable terms.
Start by tying your AI adoption goals to metrics that your business already tracks. Lead Time to Value (the elapsed time from idea to deployed feature) is one of the most revealing indicators. Defect escape rate, deployment frequency, and mean time to recover round out a useful starting set. These aren’t vanity metrics. They connect your engineering effort to outcomes that the board and customers actually care about.
Here is where many leadership teams make a costly mistake: they conflate AI adoption rate with business impact. Tracking how many engineers use an AI assistant each week tells you about tool uptake, not value creation. You need both. Set a target for adoption and a separate target for the engineering outcomes you expect that adoption to drive.
Benchmarking is your friend here. Empirical data shows a persistent perception gap between what teams believe AI is doing for them and what the metrics actually show, with AI helping low-performers more than high-performing teams, and bottlenecks simply shifting rather than disappearing without deliberate process reform. Use external benchmarks to pressure-test your internal assumptions early, before you set targets that your teams will then spend months chasing in the wrong direction.
- Define two to three primary KPIs before pilot launch, tied to speed and quality
- Set a secondary adoption metric but never treat it as the primary success signal
- Review benchmarks from comparable organizations to calibrate realistic expectations
- Identify which teams or functions are most likely to see early gains and instrument them first
- Build a feedback loop so engineers can flag when AI output is creating downstream rework
Pro Tip: Resist the urge to announce AI success based on adoption numbers alone. If your AI integration strategies are not wired to business outcomes from day one, you will spend months optimizing the wrong thing.
Select and integrate the right AI engineering stack
Once you are clear on outcomes, selecting the right stack is the engine for results.
Not all AI engineering stacks are built for enterprise scale, and the differences between them are significant enough to affect your adoption trajectory, governance posture, and ultimately your ROI timeline. Evaluating your options systematically will save you from expensive migrations later.
Here is a practical way to think through the selection process:
- Audit your current toolchain and identify where the highest-friction handoffs occur. AI works best when it fits into existing developer workflows rather than replacing them wholesale.
- Evaluate production readiness. A stack that performs brilliantly in a demo environment but struggles with your internal security controls and compliance requirements is not production-ready, regardless of what the vendor says.
- Assess extensibility. Can the stack integrate with your existing CI/CD pipeline, your code review process, and your observability tooling? Lock-in to a closed ecosystem will limit your ability to adapt as the market evolves.
- Consider governance needs. Enterprise teams need audit trails, permission controls, and the ability to enforce coding standards and security policies through the AI layer itself.
- Pilot with a representative team before committing. The learning curve and cultural fit matter as much as the technical specs.
| Stack | Adoption evidence | Code output scale | Governance maturity |
|---|---|---|---|
| Cloudflare internal stack | 93% R&D adoption, +55% merged requests | Significant volume increase | Strong internal controls |
| OpenAI Harness (Codex) | 0 manual code lines, ~1M agent-generated lines | Beta product in 1/10th time | AGENTS.md pattern, rigid architecture |
| Google ADK | Growing enterprise adoption | Multi-agent orchestration | Configurable, expanding |
The Harness engineering case is particularly instructive. Their team built a beta product with zero manual code, approximately one million lines generated by agents, in a fraction of the expected time. They achieved this by treating the AGENTS.md file as a structured map for agents, enforcing rigid architecture decisions upfront, using agents to review other agents’ output, and applying progressive disclosure of complexity. That is not an accident of tooling. It is a deliberate systems approach.

Pro Tip: Build your selection criteria around governance for AI assistants from the start. The teams that bolt on governance after adoption struggle significantly more than those who treat it as a prerequisite.
Overhaul engineering processes to avoid new bottlenecks
With the stack in place, focus shifts to workflow transformation to actually realize predicted gains.
Here is something most AI rollout plans miss entirely: deploying AI into an unreformed software development lifecycle (SDLC) rarely eliminates bottlenecks. It relocates them. Your code generation speeds up. Your code review queue explodes. You traded one problem for another, and the board still isn’t seeing the throughput improvement they were promised.
The Plandek 2026 Benchmarks make this concrete. Low-performing teams using AI reduce their Lead Time to Value by approximately 50%, which is four times the improvement seen by high-performing teams who achieve only 10 to 15% gains. Why? High-performing teams were already operating near their process ceiling. AI alone does not lift the ceiling. And for all teams, code review time remains a serious drag, with bottom-quartile performers sitting at 35 or more hours per review cycle even after AI adoption.
The practical implication is that you need to re-architect your SDLC alongside deploying AI, not after.
Specific tactics that work:
- Introduce human-in-the-loop checkpoints at the orchestration level, not just at final review. Catching misaligned agent output early is far cheaper than reviewing it at the end of a sprint.
- Restructure your code review process to account for higher volume. AI generates more code, faster. Your review capacity needs to scale proportionally, either through automation, tiered review policies, or both.
- Implement agent orchestration patterns where specialized agents handle distinct parts of the workflow (code generation, testing, documentation) so that no single step becomes a chokepoint.
- Define quality gates that AI output must clear before it reaches human reviewers. This is the only sustainable way to manage the volume increase without burning out your senior engineers.
| Metric | Pre-AI baseline | Post-AI (no process reform) | Post-AI (with process reform) |
|---|---|---|---|
| Lead Time to Value | Varies | Marginal improvement | Up to 50% reduction (low performers) |
| Code review cycle time | Baseline | Often increases | Stabilizes with tiered review |
| Defect escape rate | Baseline | Risk of increase | Improved with quality gates |
| Deployment frequency | Baseline | Limited change | Increases with CI/CD integration |
The teams optimizing engineering processes in parallel with AI deployment are the ones hitting the outcomes in their original business cases. The teams that treat AI as a drop-in addition to existing workflows are the ones quietly walking back their ROI projections at the six-month mark.
Mitigate AI-specific risks: memory, statelessness, and edge cases
Having recalibrated engineering processes, now address project-level and operational risks.
AI agents are powerful. They are also stateless by default, which creates a category of risk that traditional software engineering practices were never designed to handle. When you are running long-duration projects with multiple agents and extended context windows, the absence of persistent memory is not a minor inconvenience. It is a structural vulnerability.
Working with AI on long software projects requires curated memory management, minimum-diff implementations, treating the end user as a quality assurance function, and building specific handling for parsing edge cases, human-in-the-loop checkpoints, and agent orchestration patterns. Without these practices, context drift compounds over time. Agents begin making decisions that contradict earlier design choices because they have no memory of those choices.
Here is a practical approach to managing this risk:
- Implement structured memory artifacts. Maintain living documents (think AGENTS.md, architecture decision records, or equivalent) that agents can reference as authoritative context. These are not optional. They are the scaffolding that keeps long-running projects coherent.
- Enforce minimum-diff implementations. Instruct agents to make the smallest change that achieves the objective. Large, sweeping refactors generated by agents introduce compounding risk because reviewers cannot reliably trace the logic trail.
- Assign human QA ownership at key milestones. Do not assume agents will catch their own edge case failures. Build human review into the process at defined intervals, particularly after context-heavy tasks.
- Build parsing failure handling into your orchestration layer. AI agents encounter edge cases that break their output format or produce ambiguous results. Your infrastructure needs to detect, log, and route these failures to human resolution rather than silently propagating broken outputs downstream.
- Document agent decision logs. When an agent makes a significant architectural or implementation choice, capture it. This creates the institutional memory that stateless AI inherently cannot maintain on its own.
“The most dangerous assumption in enterprise AI engineering is that agents will maintain coherent context across long projects without explicit, curated scaffolding. They won’t. That gap is where quality quietly erodes.”
Pro Tip: Treat AI risk management as an engineering discipline in its own right. Assign ownership, build runbooks for failure modes, and review them on the same cadence as your other operational processes.
Why AI-driven engineering isn’t just about acceleration—it’s rethinking the operating model
After the practical tips, let’s challenge the way most companies view the AI-driven transformation.
Here is the uncomfortable reality that most AI engineering strategies dance around: speed is not the endgame. Every vendor pitch frames AI as an accelerator. Faster code. Faster reviews. Faster shipping. And yes, the throughput numbers in successful deployments are real. But organizations that treat AI purely as a speed multiplier are automating their existing operating model, and that is a fundamentally limited bet.
Consider the METR randomized controlled trial result that Cloudflare’s own analysis surfaces: experienced developers worked 19% slower with AI tooling on certain tasks. SWE-Bench Pro shows solve rates below 25% for frontier models on real-world software engineering problems. These are not arguments against AI. They are arguments against the naive “AI makes everyone faster, always” narrative that has infected too many enterprise roadmaps.
The organizations seeing genuine transformation are not just running faster. They are restructuring decision rights, redefining roles, and redesigning how work flows through the organization. An engineer who was previously a primary code producer becomes an orchestration specialist who directs and governs agent output. A tech lead’s job shifts from reviewing individual PRs to setting the architectural constraints that agents operate within. These are operating model changes, not productivity tweaks.
Most companies resist this because it requires acknowledging that AI adoption is not a cross-functional initiative you run alongside existing operations. It is a redesign of those operations. That is harder to scope, harder to sell internally, and harder to measure in a quarterly cycle. But it is the work that separates genuine competitive advantage from expensive theater.
The teams building AI operating models with deliberate role redesign and governance structures are the ones who will sustain their gains. Everyone else will see a productivity spike followed by a plateau, and wonder what went wrong.
Enable measurable AI impact with enterprise analytics and governance
Ready to take these strategies from theory to enterprise-level execution?
Defining the right KPIs, selecting the right stack, reforming your SDLC, and managing agent risk are all meaningful steps. But without a continuous measurement and governance layer, you are flying blind after the initial rollout. You need visibility into where AI is actually accelerating work, and where it is creating new friction you have not yet diagnosed.
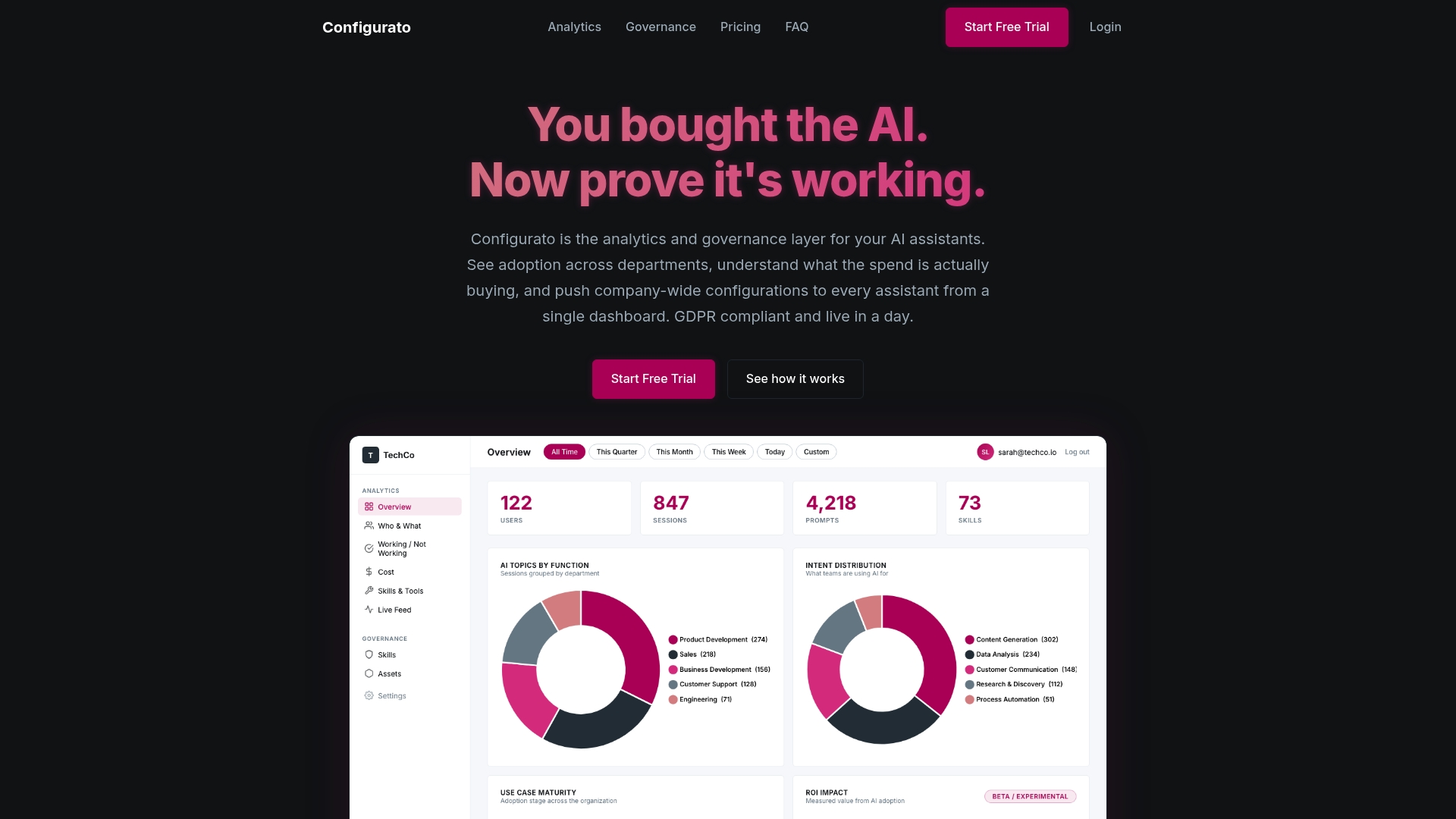
Tekkr’s Configurato platform gives CTOs and operations leads exactly that. It embeds your company’s engineering processes, quality standards, and architectural guidelines directly into the AI assistants your teams are already using. No retraining. No new workflows for engineers to adopt. Agents operate with your context baked in from the start, and you get the traceability and analytics and governance for AI-driven engineering to see what is working, what is not, and how you compare to high-performing organizations running similar configurations. If you are serious about translating AI investment into measurable engineering outcomes, this is where that work gets done.
Frequently asked questions
What is the biggest productivity driver with AI in engineering teams?
AI delivers the most significant productivity gains for low-performing teams, especially when paired with restructured workflows and clearly defined KPIs. Low-performing teams using AI reduce Lead Time to Value by approximately 50%, compared to 10 to 15% for high-performers.
How should companies measure the impact of AI on their engineering teams?
Track adoption rates, speed-to-value, code review cycle times, and business-aligned KPIs rather than tool usage metrics alone. Cloudflare’s AI stack transformation showed that meaningful measurement combines adoption rates with hard throughput data like merged request volume.
What are typical bottlenecks after deploying AI agents?
Code review time, integration friction, and orchestration complexity remain common bottlenecks even after AI adoption is high. The code review bottleneck persists at 35 or more hours for bottom-quartile performers, regardless of AI tooling in place.
Are AI code generators always faster for experienced developers?
No, empirical tests show that experienced developers can work slower with AI tooling on certain tasks. A METR randomized controlled trial found experienced developers working 19% slower with AI assistance, which underscores why blanket speed assumptions are dangerous for enterprise planning.