
Choosing the right domain-specific AI use case is one of the hardest calls an operations leader makes today. Generic benchmarks and vendor demos rarely survive contact with the messy reality of enterprise workflows, proprietary data pipelines, and regulatory requirements. The pressure to show ROI is real, and the cost of a poorly chosen pilot is not just wasted budget. It erodes organizational trust in AI at precisely the moment you need buy-in most. This article cuts through the noise with validated real-world examples, concrete metrics, and a practical framework for identifying where domain-specific AI actually delivers.
Table of Contents
- How to evaluate domain-specific AI opportunities
- Biologics manufacturing: Predictive AI’s impact at Bristol Myers Squibb
- Electronics manufacturing: Supply chain transformation with Lenovo’s AI rollout
- Lessons from benchmarks: When AI struggles with domain nuance
- What most leaders miss about domain-specific AI
- Making it actionable: Your path to compliant, effective AI at scale
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Validate with domain experts | Always combine AI with expert oversight to address edge cases and operational complexity. |
| Measure real business impact | Look for clear KPIs like cycle time, volume, or cost savings when evaluating AI projects. |
| Beware compliance pitfalls | Be proactive about regulatory and data governance needs in any domain-specific AI deployment. |
| Continuous improvement is needed | Plan for ongoing monitoring and adaptation as domain requirements and data evolve. |
How to evaluate domain-specific AI opportunities
Before looking at case studies, it is critical to clarify how to separate hype from genuine value in domain-specific AI.
Domain-specific AI refers to models and systems trained or fine-tuned on data and workflows that are unique to a particular industry or operational function. Unlike general-purpose tools, these systems are built around proprietary process knowledge. Domain-specific AI requires fine-tuning on proprietary data, often uses Retrieval-Augmented Generation (RAG) to pull from internal knowledge bases, and must be validated by subject matter experts before deployment. That last requirement matters more than most leaders realize.
The reason context knowledge is so critical comes down to edge cases. In a standard manufacturing line, for example, a generic AI model may handle routine anomaly detection reasonably well. But the moment a process deviation involves a rare raw material interaction or a regulatory hold condition, a model trained on broad public data will fail or, worse, produce a confident wrong answer. Domain-specific AI is designed to handle those moments.
Here are six factors you should evaluate before committing to any domain-specific AI initiative:
- Data quality and fit: Does your organization have sufficient labeled, structured data from the target process? Poor or sparse data is the single biggest killer of domain AI projects.
- Validation pathway: Who in your organization can validate model outputs? You need named domain experts, not just data scientists.
- Workflow integration: Can the AI fit into existing tools and systems, or does it require a parallel workflow that people will quietly ignore?
- Compliance requirements: In regulated industries, every model output may need to be auditable. Plan for that from day one, not after launch.
- Edge-case handling: How does the model behave when it encounters unusual inputs? Graceful degradation or confident failure?
- Cost-benefit clarity: What does success look like in measurable terms, and over what time horizon?
“Collaboration between domain and data teams is the single most important factor in overcoming the inherent limitations of AI in specialized contexts. Neither group succeeds alone.”
Research on human-AI collaboration consistently shows that hybrid teams outperform AI-only approaches on specialized tasks. This finding should shape how you structure every pilot you run.
Pro Tip: Pilot domain-specific AI only in processes where you have clear measurement baselines and a named person accountable for validating outputs. Without both, you will not be able to distinguish a model problem from a data problem from a user adoption problem.
It is also worth thinking carefully about AI governance considerations before you scale. Governance is not a compliance checkbox. It is the operational infrastructure that keeps a working pilot from becoming a liability at scale.
Biologics manufacturing: Predictive AI’s impact at Bristol Myers Squibb
Now, let us examine a proven example from pharmaceuticals, a sector with rigid requirements and high variability.
Bristol Myers Squibb deployed domain-specific predictive AI at its Devens, Massachusetts biologics facility. The context matters here. Biologics manufacturing involves living cell cultures, complex process parameters, and regulatory scrutiny that makes most manufacturing environments look simple. Variability is not an edge case. It is a constant feature of the process.

The AI system was trained on facility-specific process data, not generic pharmaceutical benchmarks. It built predictive models for new product introduction cycles, production yields, and environmental outputs. Critically, scientific staff were involved in model validation from the start. This is not a story about replacing scientists. It is a story about giving them tools that compress the time between process insight and operational decision.
The results were substantial. Bristol Myers Squibb cut NPI time by 42%, increased manufacturing volume by over 40%, and reduced emissions by more than 40% through domain-specific predictive AI.
| Metric | Before AI | After AI | Change |
|---|---|---|---|
| New product introduction cycle time | Baseline | 42% reduction | Faster |
| Biologics manufacturing volume | Baseline | 40%+ increase | Higher |
| Facility emissions | Baseline | 40%+ reduction | Lower |
| Scientific workflow integration | Manual review | AI-assisted | Streamlined |
These numbers are not incremental. A 42% reduction in NPI cycle time, in an industry where months of delay mean delayed patient access and significant revenue impact, is transformational. And the emissions reduction was not a side project. It emerged from more precise process control enabled by the same predictive models.
Several factors made this work. The data was rich and specific to the Devens facility. Scientific experts were embedded in the validation process. And the AI system was designed to support existing scientific workflows rather than replace them with a parallel system that staff would have to manage on top of their regular responsibilities.
Pro Tip: In highly regulated environments, model validation against process variability is not optional. Build your validation cadence into the project plan before you write a single line of model code, and make sure you have insights for compliance in AI embedded in your governance structure from the start.
The BMS case illustrates a broader principle. The industries where AI seems hardest to apply, because of regulation, variability, and expert knowledge requirements, are often the ones where domain-specific AI delivers the most value. The difficulty is the moat.
Electronics manufacturing: Supply chain transformation with Lenovo’s AI rollout
Beyond pharmaceuticals, domain-specific AI reshapes electronics manufacturing at global scale.
Lenovo’s implementation at its Monterrey Global Model Factory is one of the most ambitious supply chain AI deployments in recent memory. The challenge in electronics manufacturing is not just complexity. It is speed. Lead times, logistics costs, and production scheduling interact in ways that make manual optimization practically impossible at scale. A delay in one component triggers a cascade across dozens of downstream processes.
Lenovo deployed more than 60 AI solutions across supply chain stages, covering demand forecasting, inventory optimization, logistics routing, and production scheduling. The key to making this work was not the quantity of AI solutions. It was the integration strategy. Each solution was connected to a unified data layer that gave every model access to the same operational picture.
| Supply chain metric | Pre-AI | Post-AI | Improvement |
|---|---|---|---|
| Lead time | Baseline | 85% reduction | Major |
| Logistics cost | Baseline | 42% reduction | Significant |
| Workforce productivity | Baseline | 58% gain | Substantial |
| Number of AI solutions deployed | 0 | 60+ | Full coverage |
An 85% reduction in lead time is not just an efficiency gain. It is a competitive repositioning. In electronics, where product cycles are short and customer expectations for delivery speed are aggressive, lead time is a market differentiator. Cutting it by 85% changes what you can promise customers and how you can structure procurement agreements.
The 42% logistics cost reduction compounds over time. In a high-volume manufacturing operation, logistics costs are enormous in absolute terms. Even a modest percentage improvement generates tens of millions in savings annually.
What drove success here? Three factors stand out:
- Process integration: Each AI solution was designed to fit into existing operational workflows, not create new ones.
- Unified data: A single operational data layer meant models were not working from conflicting or stale information.
- User engagement: Frontline teams were involved in the rollout, which reduced resistance and improved the feedback loop for model improvement.
The Lenovo case also shows the value of thinking about compliance and risk management in AI as a systemic concern, not a function of individual tools. When you deploy 60+ AI solutions across a facility, governance cannot be an afterthought. It has to be built into the architecture.
Lessons from benchmarks: When AI struggles with domain nuance
Finally, it is important to set realistic expectations. Benchmarks reveal when domain-specific AI hits its limits.
The AgentDS benchmark study tested autonomous AI agents across domain-specific data science tasks in multiple industries including commerce, food, healthcare, insurance, manufacturing, and retail banking. The findings are instructive and should temper any assumption that deploying domain-specific AI is a straightforward path to outperformance.
The core finding: AI-only solutions struggled with domain-specific data science tasks, and best results consistently came from mixed human-AI teams rather than autonomous agents working alone.
“Real-world productivity gains from domain-specific AI implementations typically range from 15% to 40%, but AI systems remain below expert-level performance in most specialized tasks, with the exception of tasks performed by novices where AI can accelerate output significantly.”
Here are five typical failure points the benchmarks revealed:
- Edge cases in rare but high-stakes scenarios: AI models trained even on rich domain data struggle when inputs fall outside their training distribution.
- Ambiguity in professional judgment calls: Domains like insurance underwriting or clinical healthcare involve judgment that resists codification.
- Legacy data quality: Many enterprises carry years of inconsistently structured operational data. Models trained on this data inherit its inconsistencies.
- Regulatory interpretation: Rules change, and models trained on historical regulatory logic can generate outputs that are no longer compliant.
- Overconfidence in outputs: AI systems often do not signal uncertainty effectively, which means users may act on a wrong output without realizing it.
| Task category | AI-only outcome | Human-AI hybrid outcome |
|---|---|---|
| Standard data analysis | Good | Excellent |
| Edge case handling | Poor | Good |
| Regulatory interpretation | Unreliable | Acceptable with oversight |
| Expert-level judgment | Below expert | Near expert |
| Novice-level task acceleration | Excellent | Excellent |
The takeaway is not that domain-specific AI is oversold. The BMS and Lenovo results are real and substantial. The takeaway is that those results came from implementations that treated human expertise as a permanent feature of the system, not a transitional phase on the way to full automation.
If your AI deployment plan assumes that human review requirements will shrink to zero as the model matures, you need to revisit that assumption. For risk management in regulated AI contexts especially, human-in-the-loop is not a limitation. It is a design requirement.
What most leaders miss about domain-specific AI
Here is the uncomfortable truth most vendor conversations skip. Technical success in a domain-specific AI pilot does not predict operational success at scale. The gap between a working model and a working deployment is where most enterprise AI value gets stranded.
The BMS and Lenovo cases succeeded not because the AI was particularly novel. They succeeded because organizational discipline matched technical ambition. Continuous monitoring, structured retraining cycles, cross-functional ownership, and embedded governance were features of those programs from the start. They were not retrofitted after problems emerged.
The leaders we see struggle most are the ones who treat domain-specific AI as a project with an end date. Build the model, validate it, deploy it, done. But a domain-specific AI system is more like a key employee than a piece of software. It needs ongoing context updates as your processes evolve. It needs feedback when it gets things wrong. It needs governance when the regulatory environment shifts.
Ignoring validation cadence and retraining schedules is the root cause of most domain AI regressions we observe. A model that was accurate in Q1 can be meaningfully degraded by Q3 if the underlying process data has shifted and no one has updated the model. In manufacturing or pharma, that degradation can be invisible right up until it causes a costly process failure.
The practical lesson: treat domain-specific AI as a dynamic capability, not a static tool. Assign cross-functional ownership that includes operations, IT, compliance, and the relevant domain function. Build review cycles into your operating calendar. And make governing long-term AI success a standing agenda item, not a once-a-year risk review.
One more thing worth saying plainly. The organizations that will extract the most value from domain-specific AI are not the ones with the biggest AI budgets. They are the ones that take the time to codify how great work actually gets done in their organization, and then build AI systems that reflect that knowledge. That is a people and process discipline before it is a technology discipline.
Making it actionable: Your path to compliant, effective AI at scale
The case studies above show what is possible. The benchmarks show where the risks live. The question now is how you close the gap between knowing this and acting on it systematically across your organization.
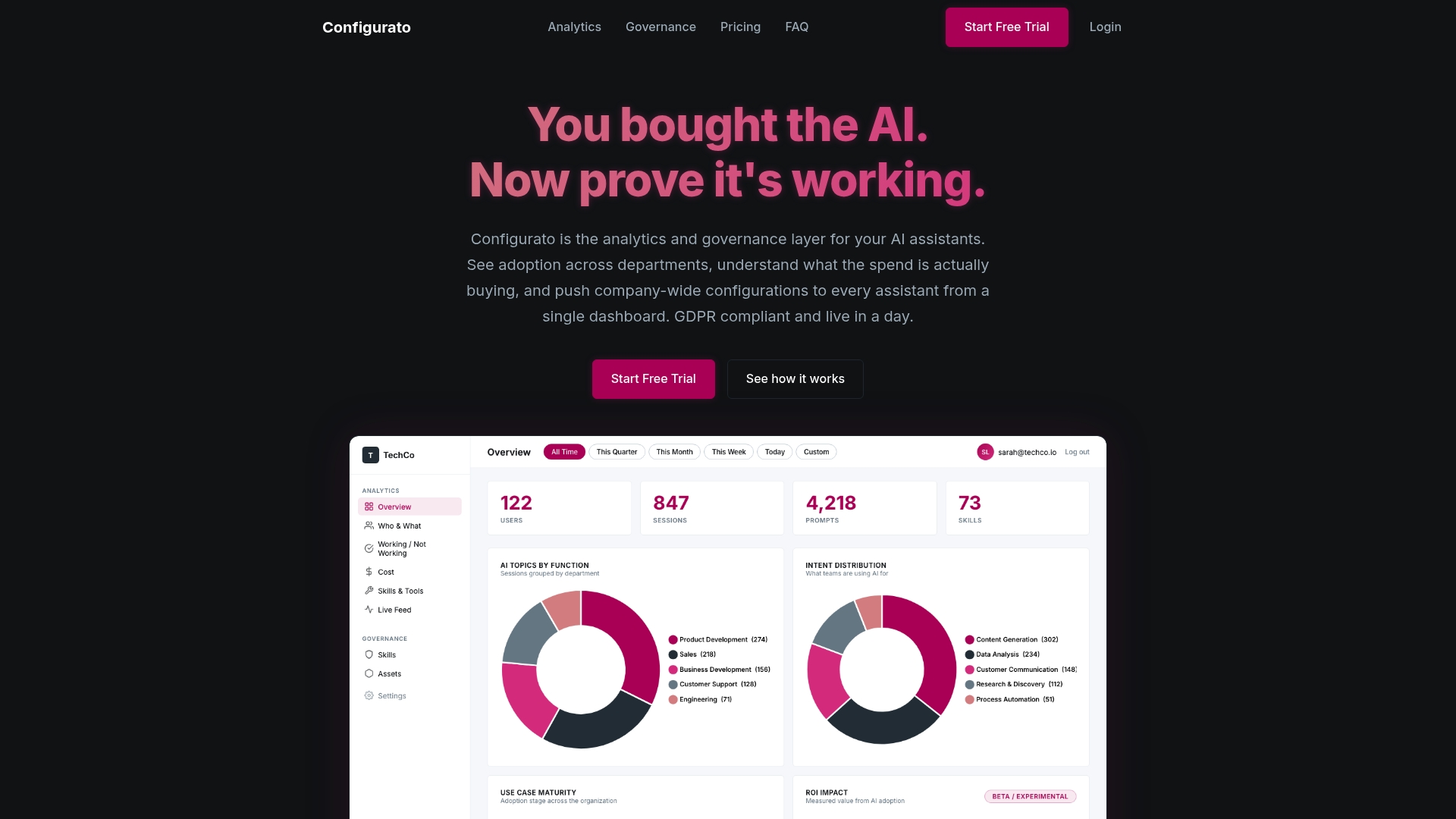
Scaling domain-specific AI requires more than good models. It requires analytics to track where AI is actually accelerating work, governance to keep outputs compliant and auditable, and the operational infrastructure to embed your company’s process knowledge into every AI interaction your teams have. That is exactly the gap that AI analytics and governance solutions are designed to address. Tekkr helps you define what great work looks like in your context, distribute that knowledge to the AI tools your teams already use, and trace where AI is genuinely moving the needle versus where adoption is high on paper and impact is low in practice. If you are ready to operationalize the lessons from BMS and Lenovo in your own environment, the next step is building the governance layer that makes it sustainable.
Frequently asked questions
What is domain-specific AI, and how is it different from generic AI?
Domain-specific AI is tailored to a narrow industry or operational context using specialized data and workflows, unlike generic AI built on broad datasets. It is fine-tuned on proprietary data and process knowledge specific to the target domain.
Which industries benefit most from domain-specific AI?
Industries with complex processes, strict compliance requirements, and specialized data see the most measurable impact. Manufacturing and pharma have demonstrated major productivity and efficiency improvements with tailored AI deployments.
What are common risks in deploying domain-specific AI?
Frequent risks include poor data quality, overfitting to niche scenarios, regulatory non-compliance, and reliance on unvalidated models. Fine-tuning risks include model degradation over time, which is especially dangerous in regulated environments where compliance is non-negotiable.
Can domain-specific AI fully replace human experts?
No. AgentDS benchmark results show that best outcomes consistently come from human-AI collaboration rather than autonomous AI, particularly for complex, ambiguous, or high-stakes processes where expert judgment is essential.