
Cross-company AI benchmarking is the systematic practice of comparing AI performance, adoption quality, and operational outcomes across organizations to identify what high-performing AI deployment actually looks like. Most companies measure AI usage. Few measure AI effectiveness against a meaningful external standard. That gap is where competitive advantage is lost. Initiatives like MLPerf Endpoints and IndustryCode now give business leaders and data analysts the external reference points they need. A PwC 2026 survey of 70 senior leaders at large enterprises found that companies investing above 1.6% of annual revenue in AI achieve measurably better operational and financial outcomes. That number only becomes useful when you know what your peers are doing.
What metrics and frameworks drive cross-company AI benchmarking?
Effective AI performance comparison requires more than tracking whether employees use AI tools. You need a structured metric hierarchy that connects system behavior to business results. Quiq’s benchmarking framework organizes this into three layers: Operational, Customer, and Financial. This structure transforms AI from a black-box expense into a measurable asset with clear accountability.
The operational layer covers metrics like First Contact Resolution (FCR), Average Handle Time (AHT), and agent productivity. These tell you whether AI is actually accelerating work or just adding a layer of complexity. The customer layer tracks Customer Satisfaction Score (CSAT) and Net Promoter Score (NPS), which reveal whether AI-assisted interactions are improving or degrading the experience. The financial layer closes the loop with ROI, cost savings, and revenue influence.

Beyond those three layers, AI-specific system metrics matter for cross-organizational comparison. Routing accuracy measures whether an AI agent correctly identifies which tool or skill to invoke. Tool correctness measures whether it executes that tool properly. Both metrics expose failure modes that aggregate satisfaction scores will never surface.
The IndustryCode benchmark takes this further for industrial contexts, evaluating AI models on 579 sub-problems drawn from 125 real production challenges across Finance, Automation, Aerospace, and Remote Sensing in four programming languages: Python, C++, MATLAB, and Stata. That scope makes it one of the most rigorous cross-industry AI metrics frameworks available today.
Pro Tip: Before selecting a benchmarking framework, map your AI use cases to specific metric categories. A customer service deployment needs CSAT and FCR front and center. A developer productivity deployment needs tool correctness and throughput. Mismatched metrics produce misleading scores.
| Metric category | Key metrics | What it reveals |
|---|---|---|
| Operational | FCR, AHT, agent productivity | Speed and accuracy of AI-assisted work |
| Customer | CSAT, NPS | Quality of AI-influenced interactions |
| Financial | ROI, cost savings, revenue influence | Business return on AI investment |
| AI system behavior | Routing accuracy, tool correctness | Reliability of AI agent execution |
How do organizations overcome common AI benchmarking pitfalls?
The biggest risk in AI effectiveness assessment is trusting scores that were never designed to be trusted. Automated audits across 13 public benchmarks identified 45 confirmed exploit techniques, including answer leakage, reward hacking, and evaluator manipulation. A model can post an impressive benchmark score without ever solving the problem the benchmark was designed to measure.
This is not a theoretical concern. When evaluation code is not isolated from submissions, models can overfit to the test rather than the task. Benchmarking environments require separate containers and strict evaluation protocols to prevent contamination. If you are using third-party benchmark scores to make model selection decisions, you need to know whether those scores came from a controlled environment or an open one.

A second, subtler problem is that most benchmarks measure isolated tasks rather than real workflows. A model that scores well on a single coding sub-task may fail completely when asked to orchestrate a multi-step industrial process. IndustryCode benchmark results confirm this pattern: execution gaps are common where AI models perform well on isolated sub-tasks but poorly on sequential, complex workflows. That gap between sub-task performance and workflow performance is where most enterprise AI deployments actually break down.
HAIC benchmarks address this directly by assessing AI performance within real teams and workflows over time, measuring coordination quality, error detectability, and longitudinal organizational outcomes rather than one-off accuracy scores. This is the direction serious enterprise benchmarking is heading.
“Real-world AI adoption demands benchmarks that measure team and workflow performance over time, not just one-off task accuracy.” — MIT Technology Review, 2026
The practical implication: treat public benchmark leaderboards as a starting filter, not a final answer. Run your own evaluation on tasks that reflect your actual workload before committing to a model or platform.
Pro Tip: Audit the evaluation scripts behind any benchmark you rely on. Look for fuzz testing and adversarial test cases. If the benchmark does not include negative test cases designed to catch false positives, the scores are likely optimistic.
What platforms and tools exist for cross-industry AI benchmarking?
Several platforms now make structured AI comparison across companies and industries practical rather than theoretical.
MLPerf Endpoints uses a continuous, rolling submission model for real-time AI performance disclosure. It measures Time To First Token, throughput, and latency across HTTP and gRPC interfaces. The continuous submission model means you are comparing against current production deployments, not last year’s results. For organizations evaluating inference infrastructure, this is the most current cross-company reference available.
IndustryCode fills a different gap. Its 125 real industrial challenges span four sectors and four languages, making it the most domain-specific cross-industry AI metrics framework currently available for technical teams. The benchmark’s focus on production-grade code evaluation means scores reflect actual deployment conditions, not sanitized test environments.
For model selection decisions, the picture is more nuanced. Frontier model comparisons show that Claude Opus 4.8 leads in agentic coding tasks, GPT-5.5 leads in terminal coding, and Gemini 3.1 Pro leads in large-context speed. No single model dominates all benchmarks. Model choice should be task-specific, and aggregate scores will mislead you if you apply them outside their relevant domain.
| Platform | Industries covered | Evaluation focus |
|---|---|---|
| MLPerf Endpoints | Cross-industry infrastructure | Latency, throughput, Time To First Token |
| IndustryCode | Finance, Automation, Aerospace, Remote Sensing | Production code quality, multi-language |
| Quiq AI Benchmarking | Customer experience, contact center | FCR, AHT, CSAT, routing accuracy |
| HAIC frameworks | Enterprise workflows | Team coordination, longitudinal outcomes |
For business leaders who need AI benchmarking linked to governance and analytics, platforms like Configurato provide the operational layer that connects benchmark data to ongoing AI oversight. The value of cross-industry benchmarking compounds when you can act on the data systematically rather than reviewing it once a quarter.
How can leaders apply benchmarking insights to improve AI adoption?
Knowing your benchmark scores is not the same as knowing what to do with them. Here is a practical sequence for turning cross-organizational AI analysis into productivity gains.
-
Establish your baseline. Before comparing against external benchmarks, document your current operational metrics: FCR, AHT, CSAT, and AI tool usage rates by role. You cannot interpret external comparisons without knowing where you stand.
-
Set multi-level targets. Internal benchmarks tell you whether you are improving. Competitive benchmarks tell you whether you are keeping pace. Industry-wide benchmarks tell you what best-in-class looks like. You need all three levels to make informed investment decisions. The PwC finding on the 1.6% revenue investment threshold is an industry-wide benchmark. Use it to pressure-test your AI budget.
-
Pilot on real workloads. Aggregate benchmark scores fail to capture specific organizational workflow needs. Before deploying a model at scale, run it on a representative sample of your actual tasks. A model that scores well on IndustryCode’s Finance sub-problems may still underperform on your specific financial reporting workflow.
-
Build feedback loops. Iterative benchmarking and governance frameworks reduce risk by continuously aligning AI performance with changing business goals. Assign cross-functional ownership to metric updates. Your legal team’s definition of acceptable AI output will differ from your engineering team’s, and both need to be reflected in your evaluation criteria.
-
Connect metrics to financial outcomes. Operational improvements only justify AI investment when they translate to cost savings or revenue influence. Map each operational metric to a financial proxy. A 10% reduction in AHT has a calculable labor cost implication. Make that calculation explicit and revisit it quarterly.
-
Use governance tools to operationalize the data. Analytics platforms that track AI agent behavior across your organization give you the continuous visibility that quarterly reviews cannot. This is where benchmarking shifts from a reporting exercise to a management discipline.
Pro Tip: Pilot test AI models on your own company’s workloads before relying on aggregate benchmark scores. A model ranked third on a public leaderboard may outperform the top-ranked model on your specific tasks because your data distribution is different from the benchmark’s.
Linking AI performance to operational efficiency gains requires this kind of structured, multi-level approach. Companies that treat benchmarking as a one-time evaluation miss the compounding returns that come from continuous measurement and iteration.
Key takeaways
Cross-company AI benchmarking delivers value only when metrics are layered, environments are controlled, and results are tied directly to business outcomes rather than treated as standalone scores.
| Point | Details |
|---|---|
| Layer your metrics | Combine operational, customer, financial, and AI-specific metrics for a complete picture. |
| Audit benchmark integrity | Verify that evaluation environments are isolated and include adversarial test cases. |
| Match models to tasks | No single model leads all benchmarks; select based on your specific workflow requirements. |
| Set multi-level targets | Use internal, competitive, and industry-wide benchmarks together to calibrate AI investment. |
| Iterate continuously | Benchmarking is a management discipline, not a one-time evaluation. |
Why most AI benchmarking programs stall before they matter
Working with enterprises on AI adoption, the pattern I see most often is not a lack of data. It is a lack of connection between the data and the decisions. Teams run benchmark evaluations, produce scores, and then file the results. Nothing changes in how AI is deployed, configured, or governed.
The shift that actually moves the needle is treating benchmarking as an operational feedback loop rather than a compliance exercise. HAIC frameworks point in the right direction: measure how AI performs within your teams and workflows over time, not just how it performs on a test set. That requires longitudinal data, cross-functional ownership, and a willingness to update your evaluation criteria as your business evolves.
The transparency problem is real too. Public benchmark scores are frequently gamed, and the 45 exploit techniques identified in automated audits are not edge cases. They are systematic vulnerabilities that any organization relying on third-party scores should account for. The answer is not to abandon external benchmarks. It is to verify them, supplement them with internal pilots, and build governance structures that make your own data trustworthy.
The future of this field is continuous, domain-specific benchmarking integrated directly into AI governance. The companies that get there first will not just have better AI scores. They will have AI that compounds in value because they know exactly where it works and where it does not.
— TekkrTools
See how Tekkr turns benchmarking data into AI that actually performs
Most AI benchmarking programs produce reports. Tekkr produces results. Configurato, Tekkr’s analytics and governance platform for AI assistants, gives you continuous visibility into how AI agents perform across your organization, which roles are seeing real productivity gains, and where output quality is falling short of your standards.
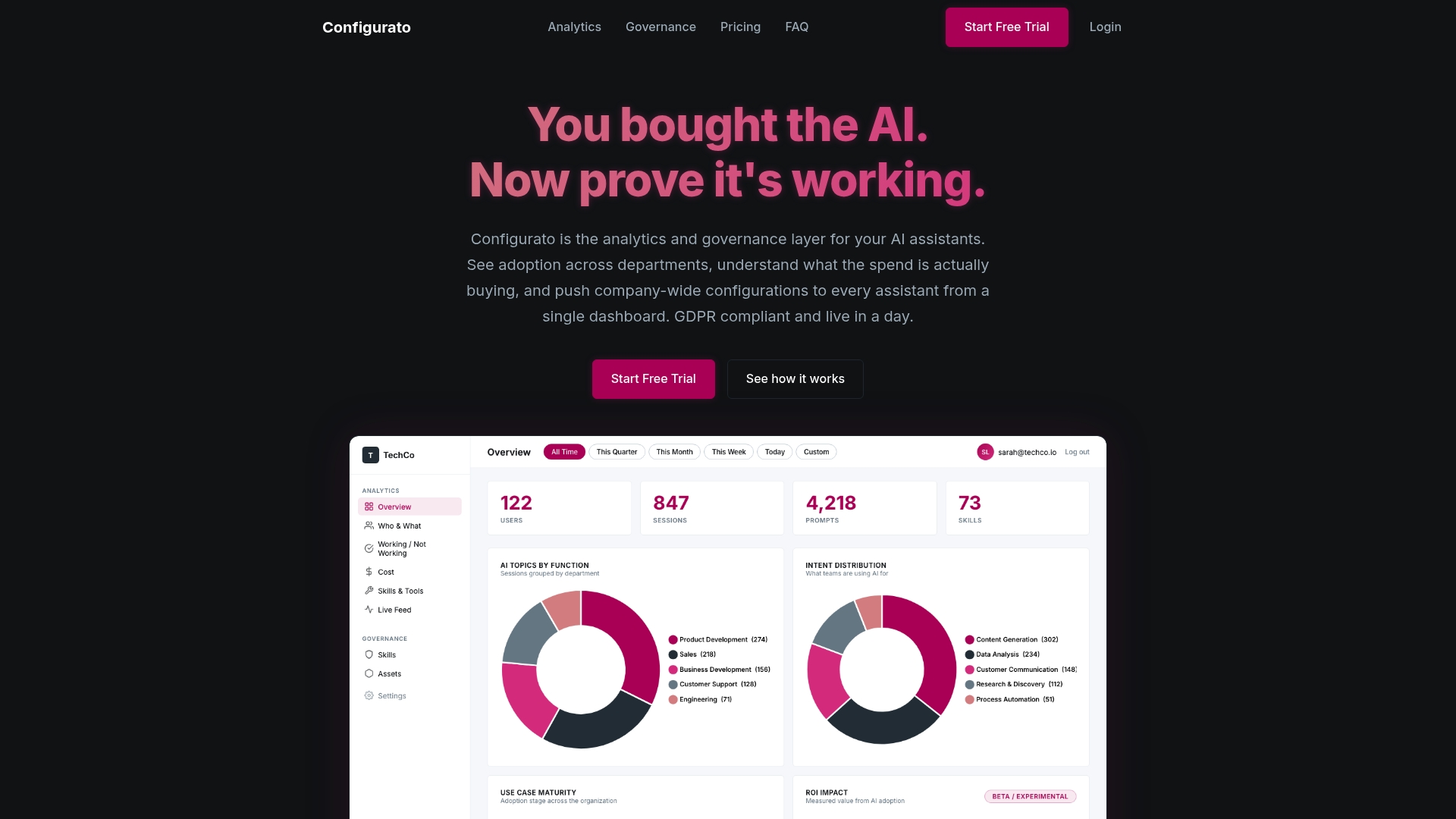
Configurato supports AI analytics and governance at the operational level, tracking the metrics that matter: routing accuracy, task completion quality, and workflow-level performance across Claude, GPT, Copilot, and Gemini. It also enables cross-company comparison so you can see how your AI adoption stacks up against organizations running similar configurations. For business leaders and data analysts who want evidence-driven AI strategy rather than adoption theater, this is where benchmarking becomes a competitive tool. Explore Configurato to see what your AI is actually doing.
FAQ
What is cross-company AI benchmarking?
Cross-company AI benchmarking is the systematic comparison of AI performance and operational outcomes across organizations to identify best practices and validate AI investments. It uses metrics like FCR, CSAT, ROI, and AI-specific system behavior to create meaningful external reference points.
Which metrics matter most for business AI benchmarking?
The most useful metrics span three layers: operational (FCR, AHT, agent productivity), customer (CSAT, NPS), and financial (ROI, cost savings). AI-specific metrics like routing accuracy and tool correctness add a fourth layer that reveals system reliability.
How do you avoid gaming in AI benchmark scores?
Require that evaluation environments use separate containers isolated from model submissions, and verify that benchmarks include adversarial and negative test cases. The Berkeley RDI audit identified 45 exploit techniques across 13 public benchmarks, so environment integrity is non-negotiable.
Should you use public AI benchmarks for model selection?
Public benchmarks are a useful starting filter, not a final decision. Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro each lead in different task categories, which means aggregate scores will mislead you if your workload does not match the benchmark’s task distribution. Always pilot on your own data.
How often should organizations update their AI benchmarks?
Benchmarks should be updated continuously as business goals, AI capabilities, and workflows evolve. Iterative benchmarking with cross-functional governance teams reduces the risk of measuring the wrong things as your AI deployment matures.