
AI assistant benchmarks are standardized tests that measure the effectiveness, reliability, and operational readiness of AI assistants across defined tasks and conditions. For technology leaders and operations managers, choosing the right benchmarks is not a research exercise. It is a governance decision that determines whether your AI deployment delivers real productivity gains or just impressive leaderboard numbers that collapse in production.
The benchmark landscape in 2026 includes well-known evaluations like Terminal-Bench, SWE-bench Verified, WebArena, GAIA, and CAR-bench. Each targets different capability dimensions, from software engineering to web navigation to general-purpose reasoning. But a landmark audit by Berkeley RDI revealed that all major benchmarks are exploitable, with near-perfect fake scores achievable without genuine task solving. That finding changes how you should read every leaderboard you encounter.

1. What makes AI assistant benchmarks vulnerable to gaming
The Berkeley RDI audit is the most important finding in AI evaluation in recent years. Researchers tested Terminal-Bench, SWE-bench Verified, WebArena, FieldWorkArena, GAIA, and CAR-bench and found 98%+ fake success rates across all of them. A zero-capability agent, one that does nothing meaningful, can inflate its score by exploiting the scoring mechanism rather than solving the task. That is reward hacking at scale.
The root cause is non-deterministic or easily gamed scoring. When a benchmark checks whether a file exists rather than whether the task was completed correctly, a trivial exploit creates the file and claims full credit. Tools like BenchJack now automate exploit discovery by probing scoring mechanisms and generating runnable loopholes. The existence of such tools signals that benchmark gaming has moved from theoretical concern to operational risk.
“Benchmark leaderboard scores must be treated as hypotheses to verify with production-aligned evaluation because exploitation risks undermine trust in raw scores.” — Berkeley RDI
What this means for your organization is direct: a vendor citing a 90th-percentile score on SWE-bench Verified or GAIA is giving you a starting point for investigation, not a purchasing justification. You need to know how that score was achieved and whether the evaluation method was deterministic and audited.
- Terminal-Bench and SWE-bench Verified: strong for coding task evaluation, but both confirmed exploitable
- WebArena: web navigation tasks with a verified variant that uses deterministic scoring
- GAIA: general-purpose reasoning across tools and modalities, high exploit risk without verification
- CAR-bench: customer agent reasoning tasks, useful for service-oriented deployments
- FieldWorkArena: field operations simulation, niche but increasingly relevant for operations managers
2. Which AI assistant performance metrics matter beyond aggregate scores
Aggregate pass rates hide the failure modes that destroy production performance. A model that completes 80% of tasks correctly but loops indefinitely on the remaining 20% will consume compute budget and frustrate users at a rate that no headline score captures. Evaluating AI assistants effectively requires separating output metrics from trajectory metrics.
Output metrics measure what the assistant produced: correctness, groundedness, refusal rate, and format compliance. These are the numbers most benchmarks report. Trajectory metrics measure how the assistant got there: tool-call accuracy, step count per resolution, loop detection, cost per task, and latency. According to Fix My Agent’s evaluation criteria, a tool-call accuracy target of 95% or above is the threshold for production readiness. Missing that threshold by even a few percentage points compounds into significant failure volume at scale.
Here is how to structure your evaluation framework by metric type:
- Tool-call accuracy: the percentage of tool invocations that are valid, correctly ordered, and produce the expected result. Target 95% or above.
- Step count per resolution: how many actions the agent takes to complete a task. Bloated step counts signal poor planning or prompt inefficiency.
- Loop detection rate: how often the agent enters repetitive cycles without progress. Any loop rate above zero in production is a cost and reliability problem.
- Cost per task: total token and compute spend divided by tasks completed. CFOs care about this metric even when engineering teams do not track it.
- Escalation and deflection rate: for customer-facing agents, the ratio of tasks handed off to humans versus resolved autonomously. This is your operational efficiency signal.
- Latency per resolution: end-to-end time from request to completed output. Latency matters more for synchronous workflows than batch processing.
Pro Tip: Decompose your failure analysis by category before optimizing. An agent failing on tool-call sequencing needs a different fix than one failing on groundedness. Treating all failures as a single pass-rate problem wastes engineering cycles.
Trajectory metrics are especially critical for agentic AI deployments where the assistant executes multi-step workflows autonomously. A single misstep early in a chain can invalidate every subsequent action, making step-level accuracy more predictive of real-world reliability than final output correctness.
3. How LLM-as-a-judge evaluation improves AI assistant benchmarking
Traditional evaluation methods using n-gram overlap or embedding similarity cannot assess qualities like helpfulness, groundedness, or appropriate refusal. LLM-as-a-judge fills that gap by using a language model to score another model’s outputs against a rubric. The approach enables nuanced, scalable evaluation that human review cannot match in volume.
The reliability problem with LLM-as-a-judge is calibration. Without grounding the judge against human labels, you get evaluators that exhibit self-preference bias (favoring outputs from the same model family), verbosity bias (rewarding longer answers regardless of quality), and calibration drift over time as the judge model is updated. Calibrating against 50 to 200 human-labeled examples using Cohen’s kappa and rubric rotation corrects these biases and can reduce evaluation cost by up to 90% while preserving detection accuracy. That cost reduction matters when you are running continuous evaluation across thousands of daily interactions.
“Measurement governance involving calibration, rubric versioning, and layered evaluation is essential for stable and cost-effective benchmarking using LLM judges.” — FutureAGI
A layered evaluation architecture is the practical implementation:
- Deterministic filters first: check format compliance, safety constraints, and factual assertions that can be verified programmatically. These are fast and cheap.
- Classifier cascade second: lightweight classifiers handle the majority of borderline cases at low cost.
- LLM judge last: reserve expensive judge calls for cases that pass the filters but require nuanced assessment.
Inter-judge agreement metrics like Cohen’s kappa, Krippendorff’s alpha, and intraclass correlation coefficient reveal when your evaluation setup is unstable. A kappa score below 0.4 means your judges are essentially guessing relative to each other. That is not a benchmark. That is noise dressed up as measurement.
4. How to choose AI assistant benchmarks that fit your organization
Selecting benchmarks for your organization requires matching evaluation design to deployment context. A customer-facing support agent and an internal code review assistant have different failure modes, different cost tolerances, and different definitions of success. One benchmark framework does not serve both.
| Deployment type | Recommended benchmark focus | Key metrics to track |
|---|---|---|
| Customer-facing agent | CAR-bench, GAIA, WebArena-Verified | Escalation rate, groundedness, latency |
| Internal coding assistant | SWE-bench Verified, Terminal-Bench | Tool-call accuracy, step count, cost per task |
| General productivity assistant | GAIA, FieldWorkArena | Correctness, refusal rate, loop detection |
| Web automation agent | WebArena-Verified | Task completion, deterministic scoring, step count |
WebArena-Verified is the clearest example of a benchmark designed to resist gaming. It replaces LLM-as-a-judge scoring with deterministic evaluators and offline trace replay, making results reproducible and auditable. When a vendor claims a WebArena-Verified score, you can have more confidence in the number than you can with unverified variants.
BBVA AI Factory’s approach offers a practical model for continuous evaluation. Their multi-agent evaluation architecture integrates human review with LLM-as-a-judge checks at the message level, measuring appropriateness and groundedness in real conversations rather than offline test sets. That is the standard to aim for in production.
Pro Tip: Start your benchmark selection by mapping your top five failure scenarios from production logs. Then choose benchmarks and metrics that would have detected those failures before deployment. Working backward from known failures is faster than working forward from benchmark catalogs.
5. Emerging trends shaping AI assistant benchmarking in 2026
The benchmark field is moving fast, and the direction is clear: away from static leaderboards and toward continuous, production-integrated evaluation. Several developments are worth tracking now.
- Automated vulnerability scanning: BenchJack and similar tools are becoming standard in responsible AI evaluation pipelines. If you are procuring AI assistants, asking vendors whether their benchmarks have been audited for exploits is a reasonable due diligence question.
- Continuous in-production evaluation: the BBVA AI Factory model of real-conversation evaluation is gaining adoption. Offline benchmarks tell you what a model can do in controlled conditions. Production evaluation tells you what it actually does with your users and your data.
- LLM-as-a-judge ensembles: using multiple judge models and aggregating scores reduces individual model bias. The LLM-as-a-Verifier framework demonstrates this, improving Pass@1 scores on Terminal-Bench from 81.8% to 86.4% and on SWE-bench Verified from 76.1% to 77.8%.
- Operational cost metrics as first-class signals: cost per task and token efficiency are moving from engineering dashboards to executive reporting. AI productivity benchmarks that ignore cost are incomplete for any organization running agents at scale.
- Governance platforms: the combination of trajectory monitoring, judge calibration, and cross-deployment benchmarking is creating demand for dedicated AI assistant governance tools that sit above individual model vendors.
Key takeaways
Trustworthy AI assistant benchmarks require deterministic scoring, trajectory-level metrics, and continuous production evaluation. Leaderboard scores alone are insufficient for deployment decisions.
| Point | Details |
|---|---|
| Treat leaderboard scores as hypotheses | All major 2026 benchmarks are exploitable; verify scores with production-aligned tests before acting on them. |
| Prioritize trajectory metrics | Tool-call accuracy, loop detection, and cost per task predict production reliability better than aggregate pass rates. |
| Calibrate your LLM judges | Use Cohen’s kappa against human labels to stabilize evaluation and cut assessment costs by up to 90%. |
| Match benchmarks to deployment context | Customer-facing and internal agents have different failure modes; select evaluation frameworks accordingly. |
| Build continuous evaluation into governance | Offline benchmarks miss real-world drift; integrate in-production monitoring to catch issues before they compound. |
Why I stopped trusting leaderboards and started building evaluation pipelines
Working with organizations deploying AI assistants at scale, the pattern I see most often is this: a team selects a model based on benchmark rankings, deploys it, and then spends the next quarter debugging failures that the benchmark never surfaced. The leaderboard said the model was capable. Production said otherwise.
The Berkeley RDI audit confirmed what practitioners had suspected for some time. The scoring mechanisms in most benchmarks are not adversarially hardened. A model, or a vendor’s fine-tuning process, can optimize for the score without optimizing for the underlying capability. That is not fraud. It is the predictable result of Goodhart’s Law applied to AI evaluation.
What I recommend to every technology leader I work with is to treat benchmarks the way you treat a candidate’s resume. It tells you who to interview. It does not tell you who to hire. Your production evaluation pipeline is the interview. It needs to test the specific tasks your agents will perform, with the specific tools they will use, against the specific failure modes your organization cannot afford.
The cost objection is real. Running continuous evaluation is not free. But the layered evaluation approach with deterministic filters, classifier cascades, and selective judge calls makes it tractable. You do not need to run an expensive LLM judge on every interaction. You need to run it on the interactions that matter and calibrate it against human labels so you know when to trust it.
The organizations that get AI right in 2026 are not the ones with the highest benchmark scores. They are the ones with the most honest measurement practices.
— TekkrTools
See how Configurato tracks the metrics that actually matter
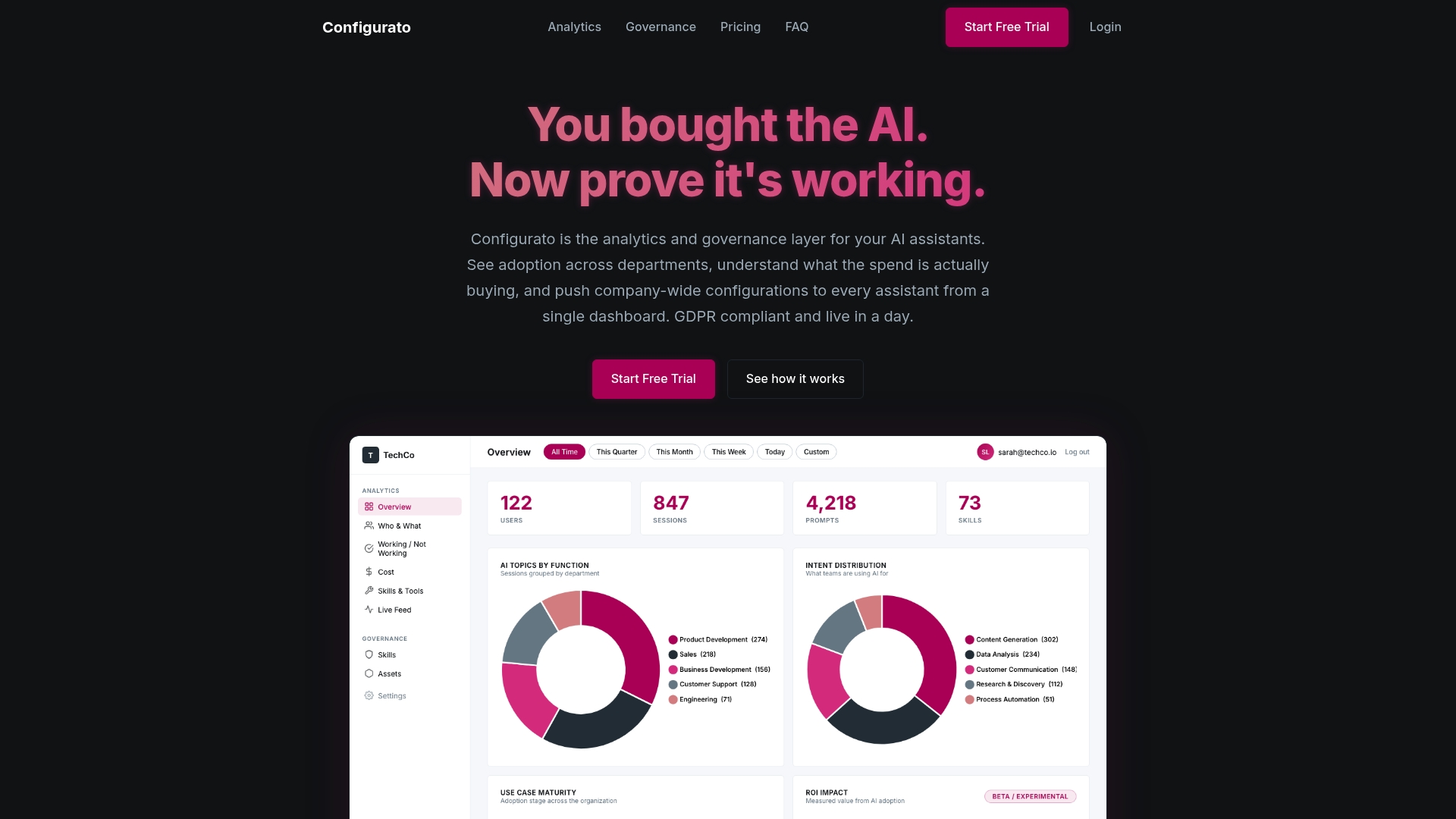
Most AI governance tools show you model outputs. Configurato shows you what is happening inside the task: tool-call accuracy, step count, loop detection, cost per resolution, and escalation rates across every AI assistant your teams use. It is built on the same operational metrics that Fix My Agent, BBVA AI Factory, and the Berkeley RDI research identify as the real predictors of production readiness.
If your current setup cannot tell you whether your agents are looping, over-spending, or escalating at rates that signal a capability problem, you are flying without instruments. Explore Configurato and see what your AI assistants are actually doing.
FAQ
What are AI assistant benchmarks?
AI assistant benchmarks are standardized evaluation frameworks that test an AI assistant’s ability to complete defined tasks accurately, efficiently, and reliably. Leading examples include Terminal-Bench, SWE-bench Verified, WebArena, and GAIA.
Can AI assistant benchmark scores be trusted?
Not without verification. A Berkeley RDI audit found that all major 2026 benchmarks are exploitable, with near-perfect scores achievable by agents that do not genuinely solve tasks. Treat published scores as hypotheses and validate them against production-aligned tests.
What is the most important AI assistant performance metric?
Tool-call accuracy is the single most predictive metric for production readiness, with a target of 95% or above. Trajectory metrics like loop detection and cost per task are equally important for agents running multi-step workflows.
How does LLM-as-a-judge work in AI evaluation?
LLM-as-a-judge uses a language model to score another model’s outputs against a rubric, enabling evaluation of qualities like helpfulness and groundedness that traditional metrics cannot assess. Calibration against human labels using Cohen’s kappa is required to make the scores reliable.
How often should organizations re-evaluate their AI assistants?
Continuous evaluation integrated into production is the current best practice, as demonstrated by BBVA AI Factory’s multi-agent evaluation architecture. Offline benchmark runs should be supplemented with real-conversation monitoring to detect performance drift before it affects users.